
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 주가예측
- 머신러닝
- 흐름도
- 주식연습
- CLI
- 가격맞히기
- 템플릿
- 딥러닝
- API
- 파이썬
- PyTorch
- 알고리즘
- DeepLearning
- 연습
- 코딩
- 코딩테스트
- 재귀함수
- 추천시스템
- 선형회귀
- Regression
- 주식매매
- 주식
- 게임
- 프로그래머스
- Linear
- 기초
- 크롤링
- tensorflow
- python
- 회귀
- Today
- Total
코딩걸음마
[딥러닝] Pytorch 슬라이싱/합치기(concat),stack/split,chunk/ index_select 본문

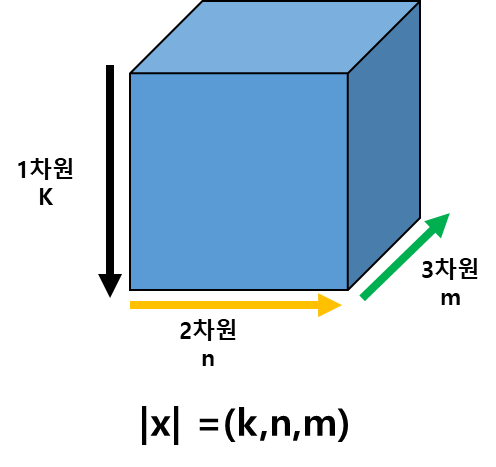
Tensor도 DateFrame 처럼 자르고, 합치고, 쪼개고, 인덱싱하고, stack할 수 있습니다.
x = torch.FloatTensor([[[1, 2],
[3, 4]],
[[5, 6],
[7, 8]],
[[9, 10],
[11, 12]]])
print(x.size())
torch.Size([3, 2, 2])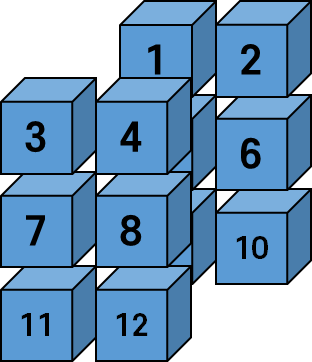
1. 인덱싱(indexing)과 슬라이싱(Slicing)
Pytorch에서 indexing과 slicing은 Pandas와 비슷하게(아니 똑같이...) 작동합니다.
하지만 차원이 늘어난 만큼 이해하기 난해하므로, 예시를 보면서 한번 익혀봅시다!
pandas처럼 인덱싱을 해봅시다. 2번째 dataset가 나올거라 예상하면서요.
x[1]과연 어느 차원의 2번째 일까요?
tensor([[5., 6.],
[7., 8.]])
위의 그림에서 x[1]은 1차원에서 2번째를 의미한다는 것을 알 수 있습니다.
그밖에도 다양한 예시를 봅시다.
x[2,1]tensor([11., 12.])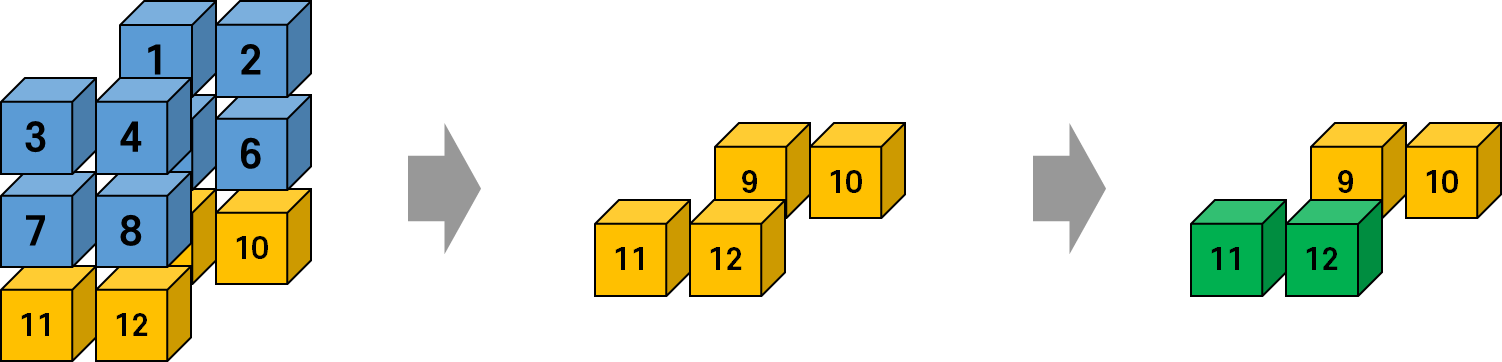
x[2,1,0]tensor(11.)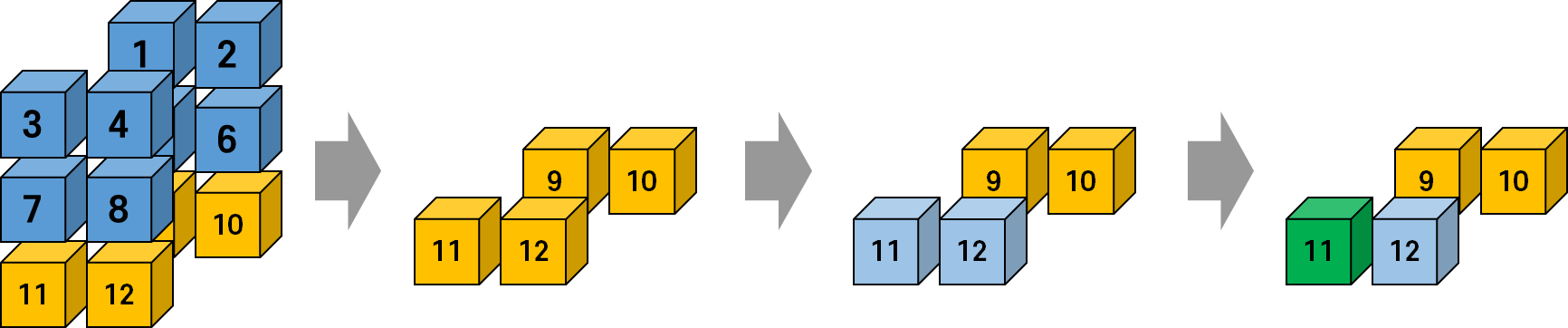
물론 : (콜론)도 사용 가능합니다.
x[1:,1:,-1]
2. cat/stack
2-1. cat(합치기)
때로는 Tensor를 합치기도 해야겠죠?
Tensor를 합칠때에는 차원을 지정해주어야합니다.
torch.cat([x, y], dim=0) 라고 작성하면 1차원을 기준으로 합쳐주죠.
2차원 Tensor를 1차원을 기준으로 합쳐봅시다.
x = torch.FloatTensor([[1, 2],
[3, 4]])
y = torch.FloatTensor([[5, 6],
[7, 8]])
print(x.size(), y.size())torch.Size([2, 2]) torch.Size([2, 2])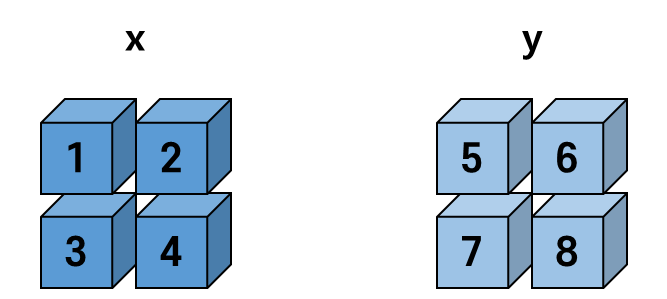
z = torch.cat([x, y], dim=0)
print(z)
print(z.size())tensor([[1., 2.],
[3., 4.],
[5., 6.],
[7., 8.]])
torch.Size([4, 2])
2차원을 기준으로 합친다면 어떻게 될까요?
z = torch.cat([x, y], dim=1)
print(z)
print(z.size())tensor([[1., 2., 5., 6.],
[3., 4., 7., 8.]])
torch.Size([2, 4])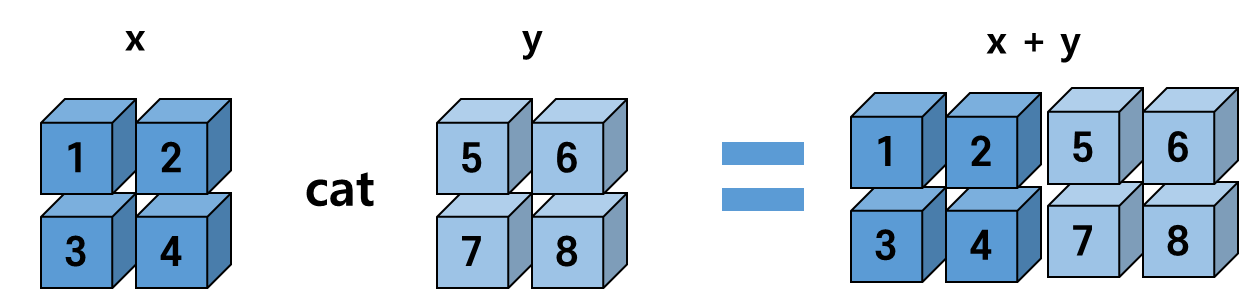
이제 3차원 Tensor를 합쳐봅시다.
x = torch.FloatTensor([[[1, 2],
[3, 4]]])
y = torch.FloatTensor([[[5, 6],
[7, 8]]])
print(x.size(), y.size())torch.Size([1, 2, 2]) torch.Size([1, 2, 2])z = torch.cat([x, y], dim=0)
print(z)
print(z.size())tensor([[[1., 2.],
[3., 4.]],
[[5., 6.],
[7., 8.]]])
torch.Size([2, 2, 2])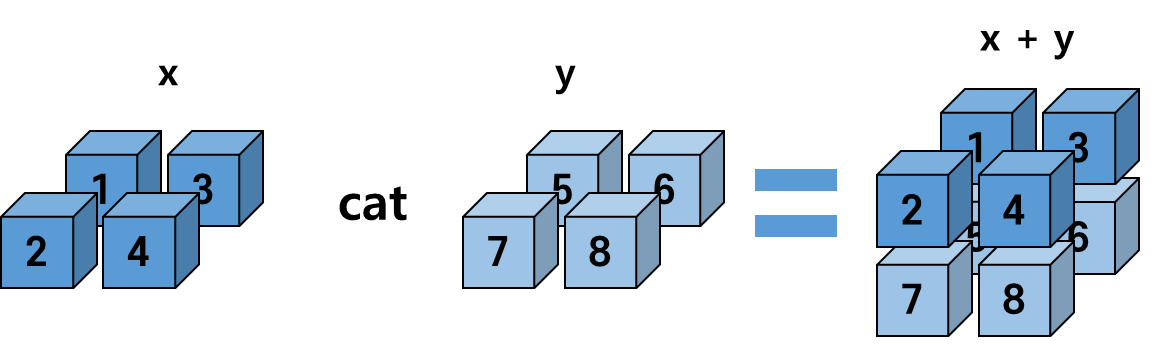
z = torch.cat([x, y], dim=1)
print(z)
print(z.size())tensor([[[1., 2.],
[3., 4.],
[5., 6.],
[7., 8.]]])
torch.Size([1, 4, 2])
2-2. stack
x = torch.FloatTensor([[1, 2],
[3, 4]])
y = torch.FloatTensor([[5, 6],
[7, 8]])
print(x.size(), y.size())torch.Size([2, 2]) torch.Size([2, 2])2차원 Tensor 간 stack을 실행 결과는 다음과 같다
tensor([[[1., 2.],
[3., 4.]],
[[5., 6.],
[7., 8.]]])
torch.Size([2, 2, 2])

2차원 Tensor 간 stack을 실행 결과는 다음과 같다
x = torch.FloatTensor([[[1, 2],
[3, 4]]])
y = torch.FloatTensor([[[5, 6],
[7, 8]]])
print(x.size(), y.size())torch.Size([1, 2, 2]) torch.Size([1, 2, 2])3차원 Tensor간 stack은 다음과 같다.
tensor([[[[1., 2.],
[3., 4.]]],
[[[5., 6.],
[7., 8.]]]])
torch.Size([2, 1, 2, 2])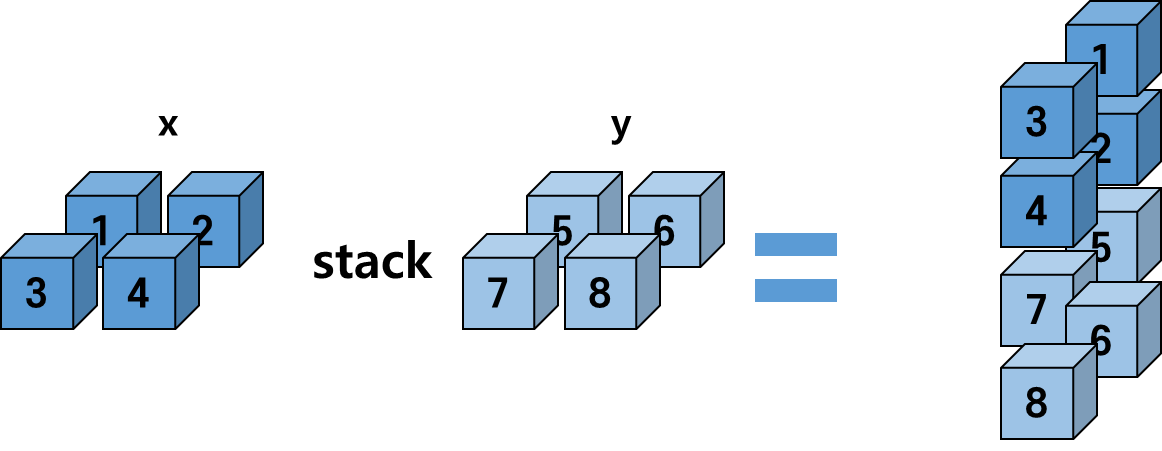
cat을 활용해서도 stack과 같은 결과를 만들 수 있는데
차원을 축소한뒤 cat을 실행하면 된다.
# z = torch.stack([x, y])
z = torch.cat([x.unsqueeze(0), y.unsqueeze(0)], dim=0)
print(z)
print(z.size())
+) 자주쓰는 용법
너무 용량이 큰 tensor를 만들면 컴퓨터가 먹통이 될수도 있다. 그러므로 tensor를 쪼개서 합칠 때 자주 쓰인다.
result = []
for i in range(5):
x = torch.FloatTensor(3, 2)
result += [x]
result = torch.stack(result)
result.size()torch.Size([5, 3, 2])resulttensor([[[2.6368e-09, 2.1027e+20],
[6.7872e-07, 2.6949e-09],
[2.6557e-06, 8.5013e-07]],
[[4.3203e-05, 2.1686e-04],
[3.3708e-06, 8.3754e-10],
[2.6728e+23, 2.7177e+23]],
[[0.0000e+00, 2.3125e+00],
[0.0000e+00, 2.3750e+00],
[0.0000e+00, 2.4375e+00]],
[[0.0000e+00, 3.6013e-43],
[2.3694e-38, 3.6013e-43],
[3.6013e-43, 0.0000e+00]],
[[0.0000e+00, 0.0000e+00],
[0.0000e+00, 0.0000e+00],
[0.0000e+00, 0.0000e+00]]])3. Split과 Chunk
data가 적다면 인덱싱이나 슬라이싱을 통해 Tensor를 분리할 수 있습니다.
하지만 아래 사진 처럼 data가 100개만 넘어가도, 헷갈리기 마련입니다.
그래서 분리하는데 규칙이 있다면 쉽게 분리할 수 있는 방법이 있습니다.
x = torch.FloatTensor(15, 20, 4)
3 - 1. Split
split은 지정한 차원의 data가 최대 data갯수가 지정한 수만큼 되도록 데이터를 분리해줍니다.
splits = x.split(7, dim=0)
for s in splits:
print(s.size())x.split(7, dim=0)은 1차원(dim=0)을 7개의 Data단위로 쪼개라는 뜻이다.
torch.Size([7, 20, 4])
torch.Size([7, 20, 4])
torch.Size([1, 20, 4])여기서 중요한 점은 1차원의 15행의 데이터를 7개씩 쪼개다가 남은 나머지의 경우 나머지만큼 남긴다는 점이다.
3차원을 기준으로 3개의 Data단위로 나누어보자.
splits = x.split(3, dim=2)
for s in splits:
print(s.size())torch.Size([15, 20, 3])
torch.Size([15, 20, 1])
3 - 2. chunk
chunk는 지정한 차원의 data를 지정한 수만큼 분할 되도록 데이터를 분리해줍니다.
split과 헷갈릴수 있는데 split은 x개씩 덩어리를 만든다면, chunk는 x개의 덩어리를 만든다는 개념으로 이해하시면 됩니다.
x = torch.FloatTensor(15, 20, 4)1차원을 기준으로 2개로 쪼개보자
chunks = x.chunk(2, dim=0)
for c in chunks:
print(c.size())torch.Size([8, 20, 4])
torch.Size([7, 20, 4])15개의 data를 쪼개서 8개 7개로 총 2덩어리로 쪼갠 것을 확인할 수 있다.
4. index_select
x = torch.FloatTensor([[[1, 2],
[3, 4]],
[[5, 6],
[7, 8]],
[[9, 10],
[11, 12]]])
print(x.size())torch.Size([3, 2, 2])
index_select는 파라미터로 지정할 차원(dim=)과 index가 있다.
그 중 index는 2개 이상 지정해줄 수도 있는데
이 경우에는 index 리스트를 torch.LongTensor를 이용하여 지정해주어야한다.
indice = torch.LongTensor([2, 0])위 코드는 3번째와 2번째 data들을 가져오는 인덱스리스트입니다.
y = x.index_select(dim=0, index=indice)
print(y)
print(y.size())
tensor([[[ 9., 10.],
[11., 12.]],
[[ 5., 6.],
[ 7., 8.]]])
torch.Size([2, 2, 2])지정한 인덱스에 해당하는 data를 조합하여 하나의 tensor로 만들어 줍니다.

'딥러닝_Pytorch' 카테고리의 다른 글
| [딥러닝] Pytorch 행렬/텐서의 곱셈(Matrix/tensor Multiplication) (0) | 2022.06.24 |
|---|---|
| [딥러닝] Pytorch 주요함수 expand/randperm/argmax/topk/masked_fill/Ones , Zeros (0) | 2022.06.24 |
| [딥러닝] Pytorch 차원다루기(Shaping/squeeze) (0) | 2022.06.23 |
| [딥러닝] Pytorch 기초연산 (0) | 2022.06.23 |
| [딥러닝] Pytorch의 기초 (0) | 2022.06.23 |



