
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
Tags
- 딥러닝
- API
- 템플릿
- 프로그래머스
- PyTorch
- Linear
- 가격맞히기
- 연습
- 선형회귀
- 머신러닝
- 회귀
- 재귀함수
- 주식
- 파이썬
- tensorflow
- 기초
- 크롤링
- 게임
- 추천시스템
- 주가예측
- 흐름도
- python
- 주식매매
- 코딩테스트
- CLI
- DeepLearning
- Regression
- 주식연습
- 코딩
- 알고리즘
Archives
- Today
- Total
코딩걸음마
종목별 테마 크롤링 코드(with Naver 금융) 본문
728x90

네이버 금융에서는 테마별 종목을 관리한다.
https://finance.naver.com/sise/theme.naver
테마별 시세 : 네이버 금융
관심종목의 실시간 주가를 가장 빠르게 확인하는 곳
finance.naver.com
테마별 수익률을 제공해주기도 하고,

테마 내 종목별 시세를 알려주기도 한다.

이 리스트를 분석에 활용하기 위해
테마별 종목 리스트를 크롤링 해보기로 했다.
import time
import pandas as pd
import requests
from bs4 import BeautifulSoup
import numpy as np
import re
#크롤링 차단 막기
seed = np.random.randint(100)
np.random.seed(seed)
r = np.random.randint(5)/10
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
thema_name_list = []
i=1
j=1
while i < 600:
global data_base
search_url = f'https://finance.naver.com/sise/sise_group_detail.naver?type=theme&no={i}'
resp = requests.get(search_url)
soup = BeautifulSoup(resp.text, 'html.parser')
s = soup.select_one
time.sleep(r)
try:
thema_name = re.sub(r"/", "_", s('head > title').text.split(':')[0])
print(thema_name)
i+=1
j=1
data_base = ["종목명", "테마 사유"]
except :
print(f"pass{i}/600")
i+=1
continue
while j<100:
try:
stock_name = re.sub("&","*",re.sub(r"\n\n", "", re.sub(r"\t", "",s(f'#contentarea > div:nth-child(5) > table > tbody > tr:nth-child({j}) > td:nth-child(2) > div > div > strong').text)).split('\n')[0]).upper()
stock_detail = re.sub(r"\n\n", "", re.sub(r"\t", "",s(f'#contentarea > div:nth-child(5) > table > tbody > tr:nth-child({j}) > td:nth-child(2) > div > div > p').text))
j+=1
data = np.array([stock_name, stock_detail])
data_base = np.vstack([data_base, data])
print(f"......종목탐색중 {j}")
except:
print("종목탐색 완료")
df = pd.DataFrame(data_base)
thema_name_list.append(thema_name)
df.to_csv(f'{thema_name}')
print(f"■■■■■■■■ 저장완료 진행도 {i}/600_")
break
arr = np.array(thema_name_list)
df =pd.DataFrame(arr)
df.to_csv('thema_name_list')
print(thema_name_list)사용 시 유의할점
"&"가 들어간 종목에 대해서는 왠지 모르지만 에러가 자꾸 발생한다.
그래서 "&"를 " * " 로 치환되어 저장된다.
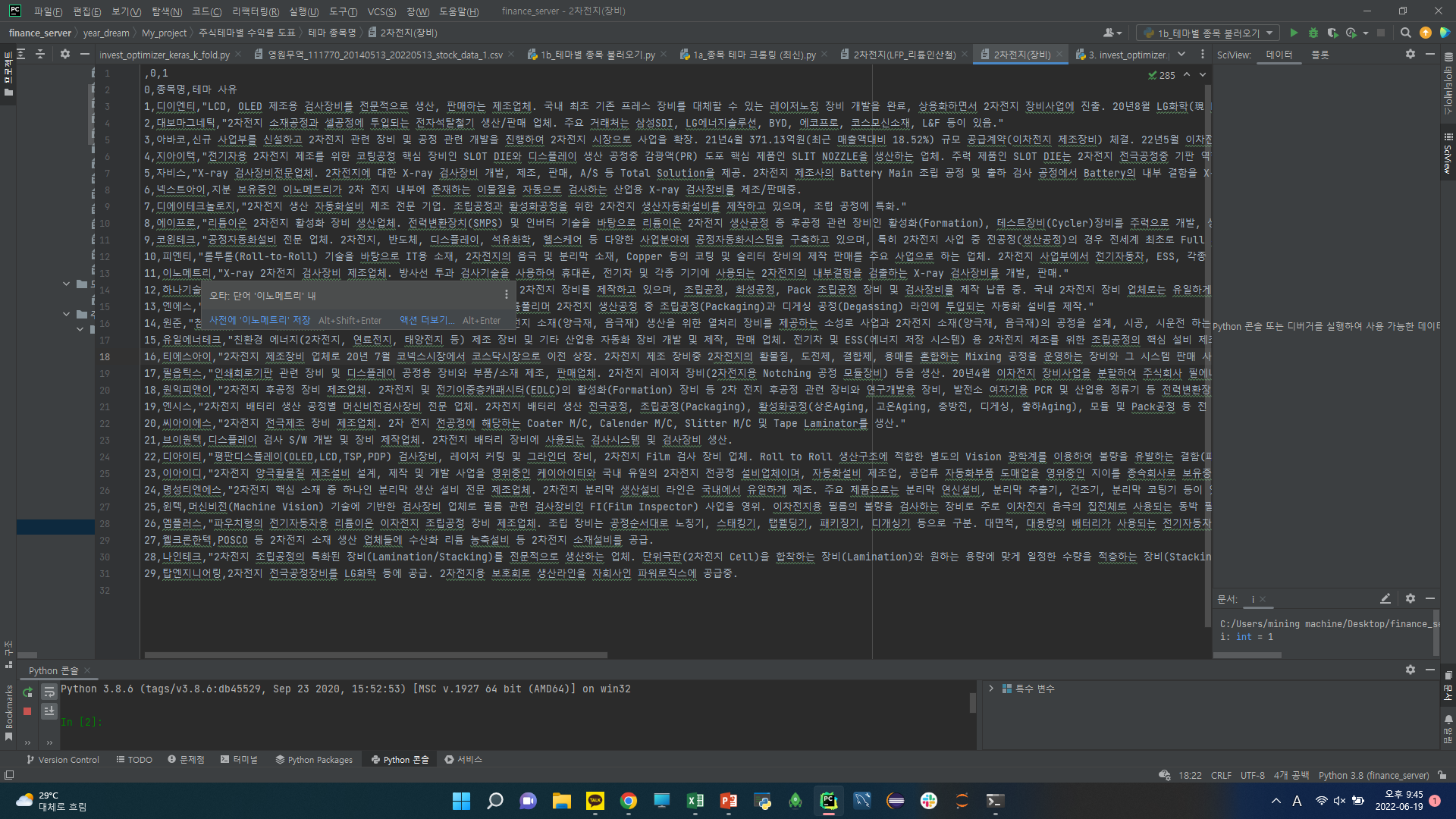
테마는 하나의 csv파일로 저장되며,
인덱스/ 종목명/ 테마사유를 가져온다.
728x90
'나만의 프로그램' 카테고리의 다른 글
| 공공데이터 API를 활용한 데이터 크롤링 방법 (ex.경주마 성적정보) (0) | 2022.07.10 |
|---|---|
| [딥러닝] 딥러닝 기본 흐름도 (0) | 2022.06.30 |
| 주식 매매시뮬레이션게임 (with 파이썬) (0) | 2022.06.20 |
| 특정기간 상승률 순위 검색기 (0) | 2022.06.20 |
| 주식 정보 불러와서 미래수익률 예측기 만들기 (with Pykrx) (0) | 2022.06.19 |
'나만의 프로그램' Related Articles
more




Comments