
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 딥러닝
- 코딩테스트
- PyTorch
- 프로그래머스
- tensorflow
- 기초
- 머신러닝
- 코딩
- 흐름도
- CLI
- python
- 알고리즘
- 주식매매
- DeepLearning
- 가격맞히기
- Linear
- 선형회귀
- 주식연습
- 주식
- 회귀
- API
- 주가예측
- 크롤링
- 템플릿
- 게임
- 재귀함수
- 파이썬
- 연습
- Regression
- 추천시스템
- Today
- Total
코딩걸음마
[머신러닝 A to Z] 머신러닝 Frame(회귀 ~클러스터링) (전처리~모델 평가) (지속 업데이트) 본문

목차
Data 불러오기/저장===========================================
1) Data 불러오기 모음(엑셀)
# xlsx 파일의 경우 설치 필요
!pip install xlrd
# 폴더 내에 파일이 있는 경우
df = pd.read_csv('/경로/경로/경로/파일명.csv')
df = pd.read_excel('/경로/경로/경로/파일명.xlsx')
# 폴더 안에 파일이 있는 경우
df = pd.read_csv('파일명.csv')
df = pd.read_excel('파일명.xlsx')
# 엑셀 파일 내 특정 시트만 불러오기
df = pd.read_csv('/경로/경로/경로/파일명.csv', sheet_name = '시트명')
df = pd.read_excel('/경로/경로/경로/파일명.xlsx', sheet_name = '시트명')
# index 컬럼 제외하고 가져오기/"Unnamed: 0" 칼럼 없이 가져오기
df = pd.read_csv('/경로/경로/경로/파일명.csv', index_col = 0)
df = pd.read_excel('/경로/경로/경로/파일명.xlsx', index_col = 0)
# xlsx 파일 오류 해결방법
!pip install openpyxl
df = pd.read_csv('/경로/경로/경로/파일명.csv',engine='openpyxl')
df = pd.read_excel('/경로/경로/경로/파일명.xlsx',engine='openpyxl')
# 엑셀 파일 내 한글 깨짐 해결 1
df = pd.read_csv('/경로/경로/경로/파일명.csv',engine='cp949')
df = pd.read_excel('/경로/경로/경로/파일명.xlsx',encoding = 'cp949')
# 엑셀 파일 내 한글 깨짐 해결 2
df = pd.read_csv('/경로/경로/경로/파일명.csv',encoding='utf-8')
df = pd.read_excel('/경로/경로/경로/파일명.xlsx',encoding='utf-8')
# 엑셀 파일 내 한글 깨짐 해결 3
df = pd.read_csv('/경로/경로/경로/파일명.csv',encoding='python')
df = pd.read_excel('/경로/경로/경로/파일명.xlsx',encoding='python')2) Data 저장하기
$ pip install xlwt
$ pip install openpyxl
# 기본 저장
df.to_csv('/경로/경로/경로/파일명.csv')
df.to_excel('/경로/경로/경로/파일명.xlsx')
# sheet name 정하기
df.to_csv('/경로/경로/경로/파일명.csv', sheet_name='new_name')
df.to_excel('/경로/경로/경로/파일명.xlsx', sheet_name='new_name')
Data 전처리===================================================
0) Data load.dataset
import seaborn as sns
df = sns.load_dataset('titanic')
df
1) Data type / 결측치 확인
방법 1)
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 15 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 survived 891 non-null int64
1 pclass 891 non-null int64
2 sex 891 non-null object
3 age 714 non-null float64
4 sibsp 891 non-null int64
5 parch 891 non-null int64
6 fare 891 non-null float64
7 embarked 889 non-null object
8 class 891 non-null category
9 who 891 non-null object
10 adult_male 891 non-null bool
11 deck 203 non-null category
12 embark_town 889 non-null object
13 alive 891 non-null object
14 alone 891 non-null bool
dtypes: bool(2), category(2), float64(2), int64(4), object(5)
memory usage: 80.7+ KB방법2)
df.isna().sum()survived 0
pclass 0
sex 0
age 177
sibsp 0
parch 0
fare 0
embarked 2
class 0
who 0
adult_male 0
deck 688
embark_town 2
alive 0
alone 0
dtype: int641-1) Data type변경
1) df Dtype 확인
df.dtype()2) df 전체 Dtype 변경
df = df.astype(int64) #int64, float64, object ...3) df 일부 Dtype 변경
df = df.astype({'col1':'object','col2':'object'})4) dtype 별로 나누기
object_ls = []
num_ls = []
for col in df.columns:
if df[f'{col}'].dtypes == 'O':
object_ls.append(col)
elif (df[f'{col}'].dtypes == 'float64')|(df[f'{col}'].dtypes == 'int64'):
num_ls.append(col)1-2) Data 결측치 시각화
결측치유무 확인
df.isna().sum()시각화
!pip install missingno
import missingno
missingno.matrix(df)
1-3) Data 결측치 제거
# 결측치가 포함된 벡터(행)를 제거
df.dropna()
# 결측치가 포함된 행 제거
df.dropna(axis = 0)
# 결측치가 포함된 열 제거
df.dropna(axis = 1)
# 결측치가 포함된 열 제거 (how) 하나라도 결측치가 있는경우 제거
df.dropna(axis = 1, how='any')
# 결측치가 포함된 열 제거 (how) 모두 결측치인 경우 제거
df.dropna(axis = 1, how='all')
# 결측치가 포함된 열 제거 (how) 모두 결측치인 경우 제거
df.dropna(axis = 1, how='all')
# 제거 후 원본 대체 여부 (inplace)
df.dropna(inplace = True) #원본 대체 함
df.dropna(inplace = False) #원본 대체 안함추천) dropna() 후 df = df.dropna() 로 override후 사용해야한다.
1-4) Data 결측치 채우기(fillna())
# 결측값을 특정한 값으로 채우기 () 안에 입력
df.fillna()
# 결측값을 다음 행의 값으로 채우기 forward
df.fillna(method='ffill')
# 결측값을 이전 행의 값으로 채우기 before
df.fillna(method='bfill')
# 결측값을 평균 값으로 채우기 mean
df.fillna(df.mean())2) Data 구조 파악
2)-1 Data 통계량 확인
Numeric한 정보만 아래와 같이 분석됨
df.describe()
Object 정보는 아래와 같이 분석됨

Count 자료 개수
Unique 고유값(분류 개수)
Top 가장 빈도수가 높은 값
freq 가장 빈도수가 높은 값의 빈도
2)-2 Data 통계량 확인
3) Data Scaling
주의) train_set, test_set을 분리 한 후, 각각 data에 대해서 Scaling 해주어야한다.
StandardScaler
기본 스케일. 평균과 표준편차 사용
이상치가 있는 경우 균형있는 척도를 보장할 수 없다.
from sklearn.preprocessing import StandardScaler
standardScaler = StandardScaler()
print(standardScaler.fit(train_data))
train_data_standardScaled = standardScaler.transform(train_data)MinMaxScaler
최대/최소값이 각각 1, 0이 되도록 스케일링
이상치가 있는 경우 균형있는 척도를 보장할 수 없다.
from sklearn.preprocessing import MinMaxScaler
minMaxScaler = MinMaxScaler()
print(minMaxScaler.fit(train_data))
train_data_minMaxScaled = minMaxScaler.transform(train_data)MaxAbsScaler
최대절대값과 0이 각각 1, 0이 되도록 스케일링
양수 데이터로만 구성된 특징 데이터에서는 MinMaxScaler와 유사하게 동작한다.
물론 큰 이상치에 민감할 수 있다.
from sklearn.preprocessing import MaxAbsScaler
maxAbsScaler = MaxAbsScaler()
print(maxAbsScaler.fit(train_data))
train_data_maxAbsScaled = maxAbsScaler.transform(train_data)RobustScaler
중앙값(median)과 IQR(interquartile range) 사용. 아웃라이어의 영향을 최소화
아웃라이어의 영향을 최소화한 기법이다.
중앙값(median)과 IQR(interquartile range)을 사용하기 때문에 StandardScaler와 비교해보면 표준화 후 동일한 값을 더 넓게 분포 시키고 있음을 확인 할 수 있다.
IQR = Q3 - Q1
from sklearn.preprocessing import RobustScaler
robustScaler = RobustScaler()
print(robustScaler.fit(train_data))
train_data_robustScaled = robustScaler.transform(train_data)
from sklearn.preprocessing import RobustScaler
from sklearn.preprocessing import robust_scale
transformer = RobustScaler()
def Robust(col_nm,df):
# scaler 사용을 위해 df를 np array로 변경
col = np.array(df[f'{col_nm}']).reshape(-1, 1)
transformer.fit(col)
col = robust_scale(transformer.transform(col))
Robust_ans = pd.DataFrame(col, columns=[f'col_nm'])
return Robust_ans
4) OHS(One Hot Encoding)
범주형(object type) Data를 분석에 용이하도록 Numeric 하게 변경해주는 방법이다.
get_dummies 를 사용하기보다는 sklearn의 OHS를 사용하는게 좋다.
예제데이터 불러오기 (diamonds)
import seaborn as sns
df = sns.load_dataset("diamonds")
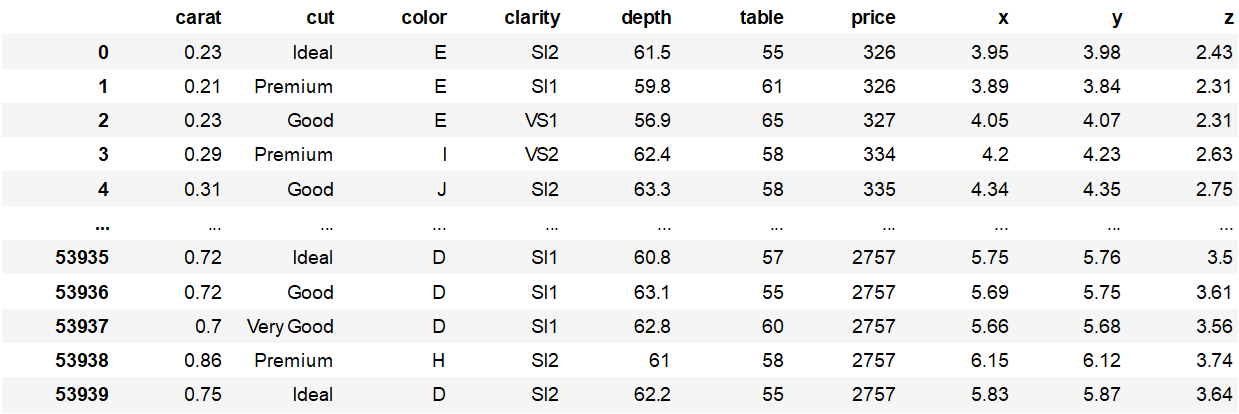
df['color'].unique()['E', 'I', 'J', 'H', 'F', 'G', 'D']
Categories (7, object): ['E', 'I', 'J', 'H', 'F', 'G', 'D']
5) -1 get_dummies() 함수
def make_dummies(df,col_nm):
df_temp= pd.get_dummies(df['{}'.format(col_nm)])
df_new = pd.merge(df,df_temp,how='left',on=df.index)
df_new = df_new.drop(['{}'.format(col_nm)], axis=1)
df_new = df_new.drop(['key_0'], axis=1)
return df_newmake_dummies(df,"color")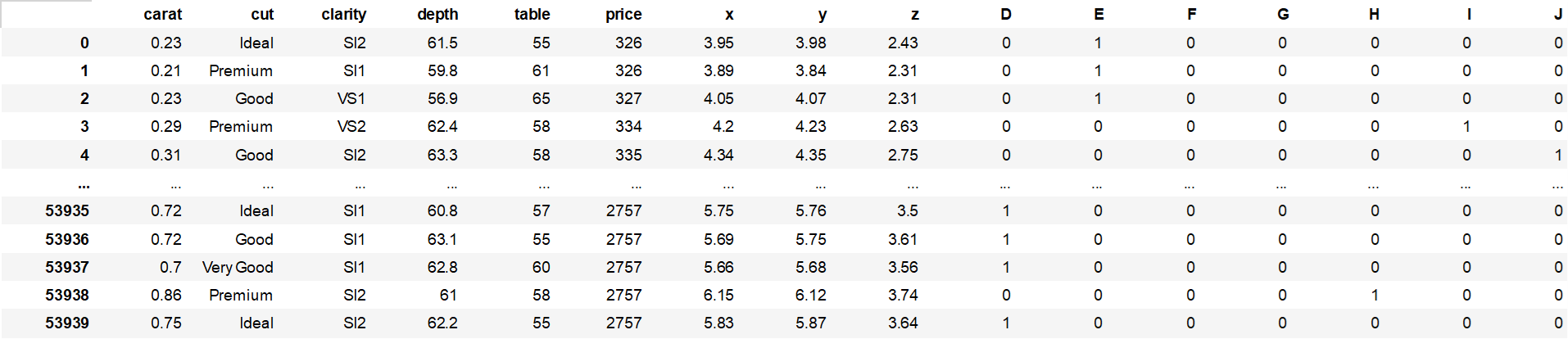
5) -2 tensorflow.keras utils 원핫인코딩 OHS
from tensorflow.keras import utils
df = utils.to_categorical(df)5) -3 sklearn.preprocessing.OneHotEncoder
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(sparse=False)
# fit_transform은 train에만 사용하고 test에는 학습된 인코더에 fit만 해야한다
df_train_encoded = ohe.fit_transform(df_train[['col']])
df_train_encoded인코딩 확인
ohe.categories_
Data 시각화===================================================
Data Feature Engineering========================================
map
apply
applymap
1) colums 합/차 정보 생성
2) colums 비율 정보 생성
3) colums 순서/ 순위 정보 생성
4) colums 구간별 정보 생성 (map)
5) Data grouping
5) -1. group별 (합/평균 등..)정보 활용하기
주의) Grouping 이후에 train test split을 group 단위로 해야한다.
# 개별 grouping
#1) 1st_col 로 먼저 구분 후, 2nd_col로 구분 한 다음 group mean을 구함
all_columns = df.columns
group_meanData = df.groupby(['1st_col','2nd_col'])[all_columns].agg('mean') #sum, std
#2) group mean의 오류값 제거
all_columns = group_meanData.replace([np.inf, np.NINF,np.nan], 0)
# 선택) group mean 값을 백분위 순위로 하는 df 생성
meanDataRank = group_meanData.groupby('matchId')[all_columns].rank(pct=True).reset_index()
#3) 기존 df와 결합
df = pd.merge(df, group_meanData.reset_index(), suffixes=["", "_mean"], how='left', on=['1st_col', '2nd_col'])Columns 조합 경우의 수 탐색
col =['mean radius', 'mean texture', 'mean perimeter', 'mean area',
'mean smoothness', 'mean compactness', 'mean concavity',
'mean concave points', 'mean symmetry', 'mean fractal dimension',
'radius error', 'texture error', 'perimeter error', 'area error',
'smoothness error', 'compactness error', 'concavity error',
'concave points error', 'symmetry error', 'fractal dimension error',
'worst radius', 'worst texture', 'worst perimeter', 'worst area',
'worst smoothness', 'worst compactness', 'worst concavity',
'worst concave points', 'worst symmetry', 'worst fractal dimension',
'class']from itertools import combinations
all_combination = []
for i in range(0,3): #몇개를 뺄건지
ls = [list(comb) for comb in list(combinations(col, len(col)-i))]
for j in range(0,len(ls)):
all_combination.append(ls[j])
print(all_combination)print(len(all_combination))
for comb in all_combination:
print(comb)
Data split====================================================
train + test
train + validation + test
from sklearn.model_selection import train_test_split
train_x, test_x, train_y, test_y = train_test_split(feateure, target, test_size=0.3, random_state=0) #test_size 0.3 30%가 test setGroup단위 split
#그룹컬럼의 unique 길이 확인!
length = len(df['그룹컬럼'].unique())
#test data로 활용할 비율 결정
sample_len = int(length*0.2)
#그룹컬럼기준 무작위 추출
split_test_ls = random.sample(list(df['그룹컬럼'].unique()),sample_len)
#test data에서 뽑힌 데이터를 제외한 그룹데이터를 train데이터로
split_train_ls =[ i for i in list(df['그룹컬럼'].unique()) if i not in split_test_ls]
df_test_x = df[df['그룹컬럼'].isin(split_test_ls) ]
df_test_y = df_test_x['target']
del df_test_x['target']
df_train_x = df[df['그룹컬럼'].isin(split_train_ls) ]
df_train_y = df_train_x['target']
del df_train_x['target']
model 적용 및 사용하기 / hyper params tuning======================
1) 회귀
2) 분류
3) 클러스터링
model 평가===================================================
model 저장/불러오기===========================================
Grid serach & Optuna=========================================
K-fold validation===============================================
'머신러닝 템플릿' 카테고리의 다른 글
| [클러스터링] K-means, DBSCAN, HDBSCAN (0) | 2022.07.20 |
|---|
