
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- 재귀함수
- 크롤링
- 게임
- 알고리즘
- CLI
- 연습
- 프로그래머스
- 주가예측
- 주식매매
- 딥러닝
- 흐름도
- 기초
- tensorflow
- 선형회귀
- 주식연습
- 코딩테스트
- 추천시스템
- 회귀
- 주식
- 파이썬
- 가격맞히기
- 템플릿
- PyTorch
- python
- Linear
- 머신러닝
- Regression
- DeepLearning
- API
- 코딩
Archives
- Today
- Total
코딩걸음마
[클러스터링] K-means, DBSCAN, HDBSCAN 본문
728x90
K-means
from sklearn.cluster import KMeans
# kmeans : 모델 객체 생성
model_km = KMeans(n_clusters=6, random_state=0).fit(datas)
# 예측 데이터 생성
pred_km = model_km.fit_predict(datas)
# 데이터 프레임 만들기
df = pd.DataFrame(datas)
df["labels"] = pred_km
df.tail(2)시각화
# 그래프 그리기
plt.scatter(df[0], df[1], c=df["labels"], cmap="rainbow", alpha=0.3)
plt.show()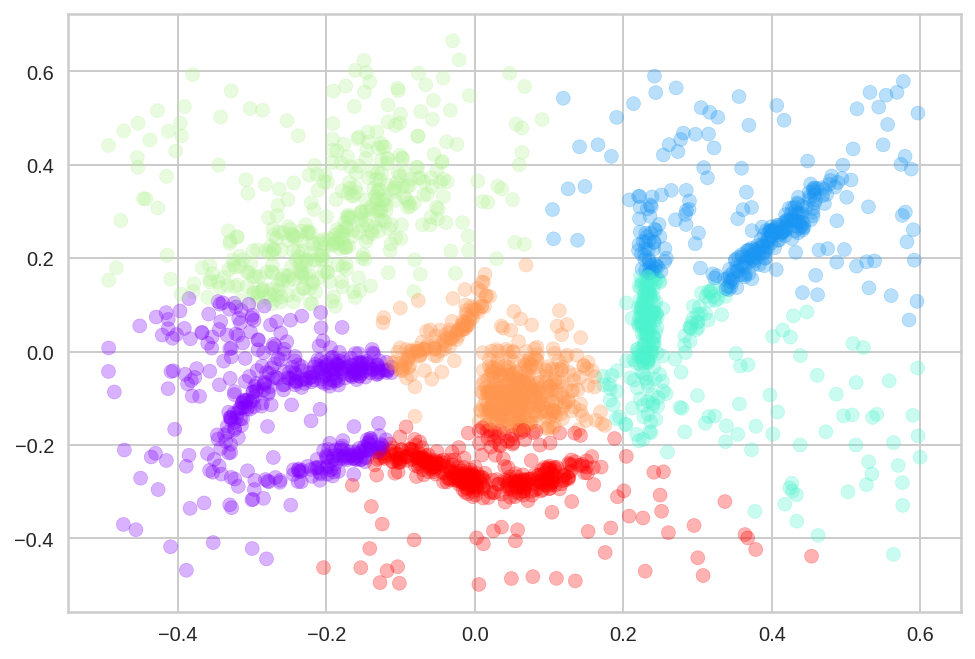
DBSCAN
from sklearn.cluster import DBSCAN
# 모델 객체 생성
model_ds = DBSCAN(eps=0.02, min_samples=3).fit(datas)
# 예측 데이터 생성
pred_ds = model_ds.fit_predict(datas)
# 데이터 프레임 만들기
df = pd.DataFrame(datas)
df["labels"] = pred_ds
df.tail(2)시각화
np.unique(df["labels"])
# 그래프 그리기
plt.scatter(df[0], df[1], c=df["labels"], cmap="rainbow", alpha=0.3)
plt.show()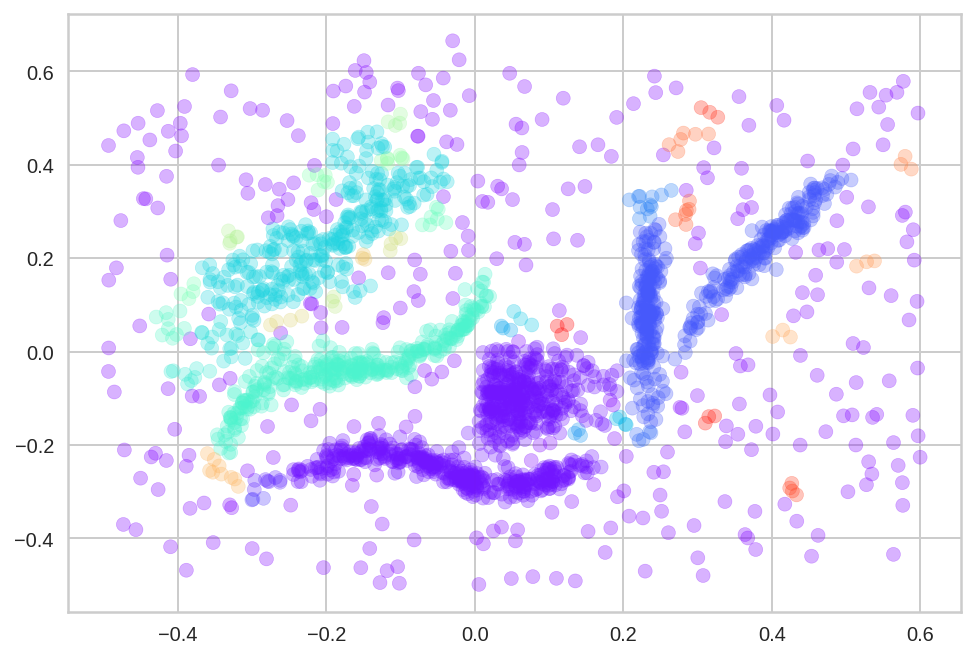
HDBSCAN
import sklearn.datasets as data
import hdbscanclusterer = hdbscan.HDBSCAN(min_cluster_size=5, gen_min_span_tree=True)
clusterer.fit(test_data)
# 클러스터를 몇개로 하면 좋을지 알려줌
clusterer.condensed_tree_.plot(select_clusters=True, selection_palette=sns.color_palette())
plt.show()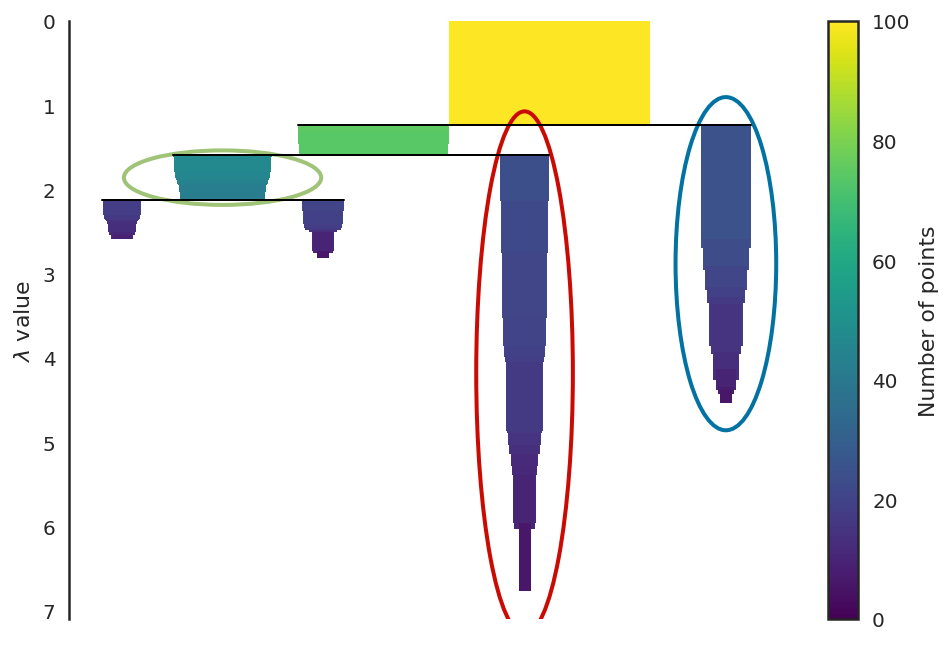
시각화
palette = sns.color_palette()
cluster_colors = [sns.desaturate(palette[col], sat)
if col >= 0 else (0.5, 0.5, 0.5) for col, sat in
zip(clusterer.labels_, clusterer.probabilities_)]
plt.scatter(test_data.T[0], test_data.T[1], c=cluster_colors, **plot_kwds)
plt.show()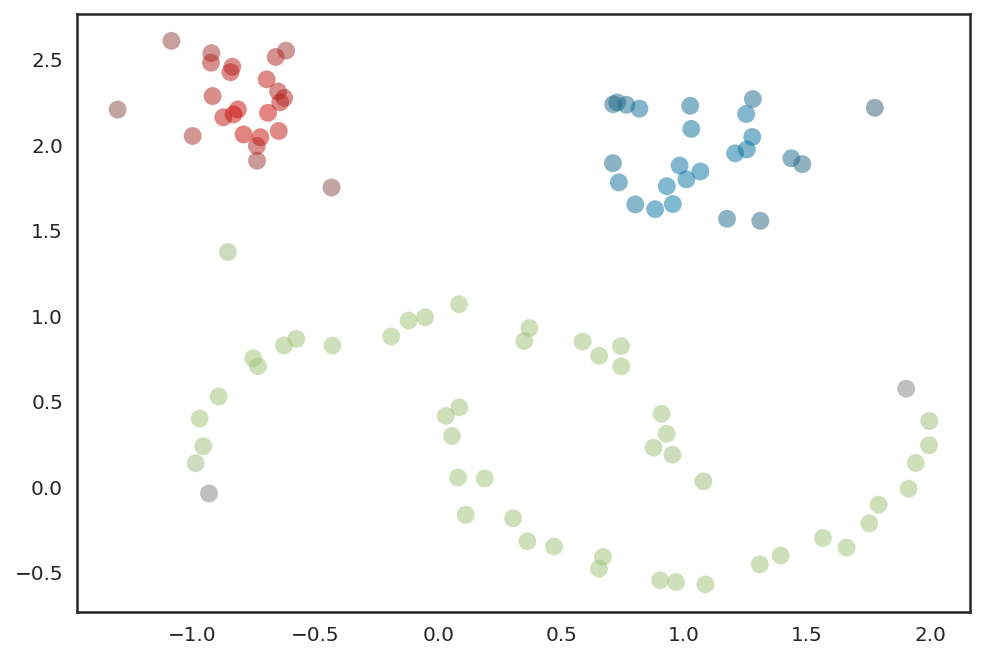
728x90
'머신러닝 템플릿' 카테고리의 다른 글
| [머신러닝 A to Z] 머신러닝 Frame(회귀 ~클러스터링) (전처리~모델 평가) (지속 업데이트) (0) | 2022.06.27 |
|---|
'머신러닝 템플릿' Related Articles
more

Comments