
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- 재귀함수
- CLI
- 주가예측
- 머신러닝
- 파이썬
- DeepLearning
- 알고리즘
- 주식연습
- 흐름도
- 가격맞히기
- Regression
- python
- 주식매매
- 코딩
- 선형회귀
- 딥러닝
- 크롤링
- 코딩테스트
- 주식
- 게임
- API
- 연습
- Linear
- 추천시스템
- tensorflow
- 템플릿
- 프로그래머스
- PyTorch
- 회귀
- 기초
Archives
- Today
- Total
코딩걸음마
[추천 시스템(RS)] CF-KNN (Collaborate Filtering K-Nearest Neighbor) 본문
딥러닝 템플릿/추천시스템(RS) 코드
[추천 시스템(RS)] CF-KNN (Collaborate Filtering K-Nearest Neighbor)
코딩걸음마 2022. 7. 16. 03:16728x90
이웃기반 알고리즘
K-최근접 이웃(K-Nearest Neighbor, KNN)은 어떤 데이터가 주어지면 그 주변(이웃)의 데이터를 살펴본 뒤 더 많은 데이터가 포함되어 있는 범주로 분류하는 방식입니다.
어떻게 보면 클러스터링 기법과 비슷하지만 여기서 사용되는 KNN은 지도학습이다.
CF-KNN은 모델이 아닌 이웃 기반 알고리즘이다.

장/단점
- 추천 리스트에 새로운 사용자 또는 아이템에 대해 안정적으로 예측이 가능하다.
- 방법이 간단하고 직관적이어서 접근이 용이하다.
- 속도가 느리며, 메모리가 많이 든다.
- 희소성(sparse matrix)으로 인한 제약이 발생한다. (유사한 이웃이 사용한 경험이 없으면 추천 불가능하다)
<소스코드>
1. 데이터 불러오기
9천여개 영화에 대해 사용자들(600여명)이 평가한 10만여개 평점 데이터를 사용해 CF-KNN을 적용해보자
import pandas as pd
import numpy as np
movies = pd.read_csv('data/movies.csv')
ratings = pd.read_csv('data/ratings.csv')
print(movies.shape)
print(ratings.shape)(9742, 3)
(100836, 4)
1-1. 영화 데이터 불러오기
데이터의 세부내용을 보면 영화 고유번호/ 영화명/ 장르분류 로 나누어져있다.
# 영화 정보 데이터
print(movies.shape)
movies

1-2. 평점 데이터 불러오기
데이터의 세부내용을 사용자 고유번호/ 평점을 매긴 영화 고유번호/ 평점/ 시간으로 구성되어있다.
# 유저들의 영화 별 평점 데이터
print(ratings.shape)
ratings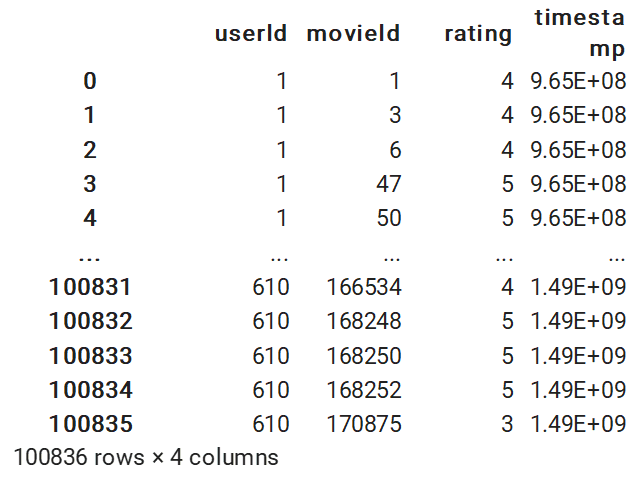
1-2. title 컬럼을 얻기 이해 movies 와 merge
rating_movies = pd.merge(ratings, movies, on='movieId')
rating_movies
2. 사용자-장르 평점 Pivot_table으로 변환
분석에 의미가 없는 timestamp 컬럼을 지운다.
ratings = ratings[['userId', 'movieId', 'rating']]
ratingspivot_table 메소드를 사용해서 행렬 변환을 시행한다.
ratings_matrix = rating_movies.pivot_table('rating', index='userId', columns='title')
ratings_matrix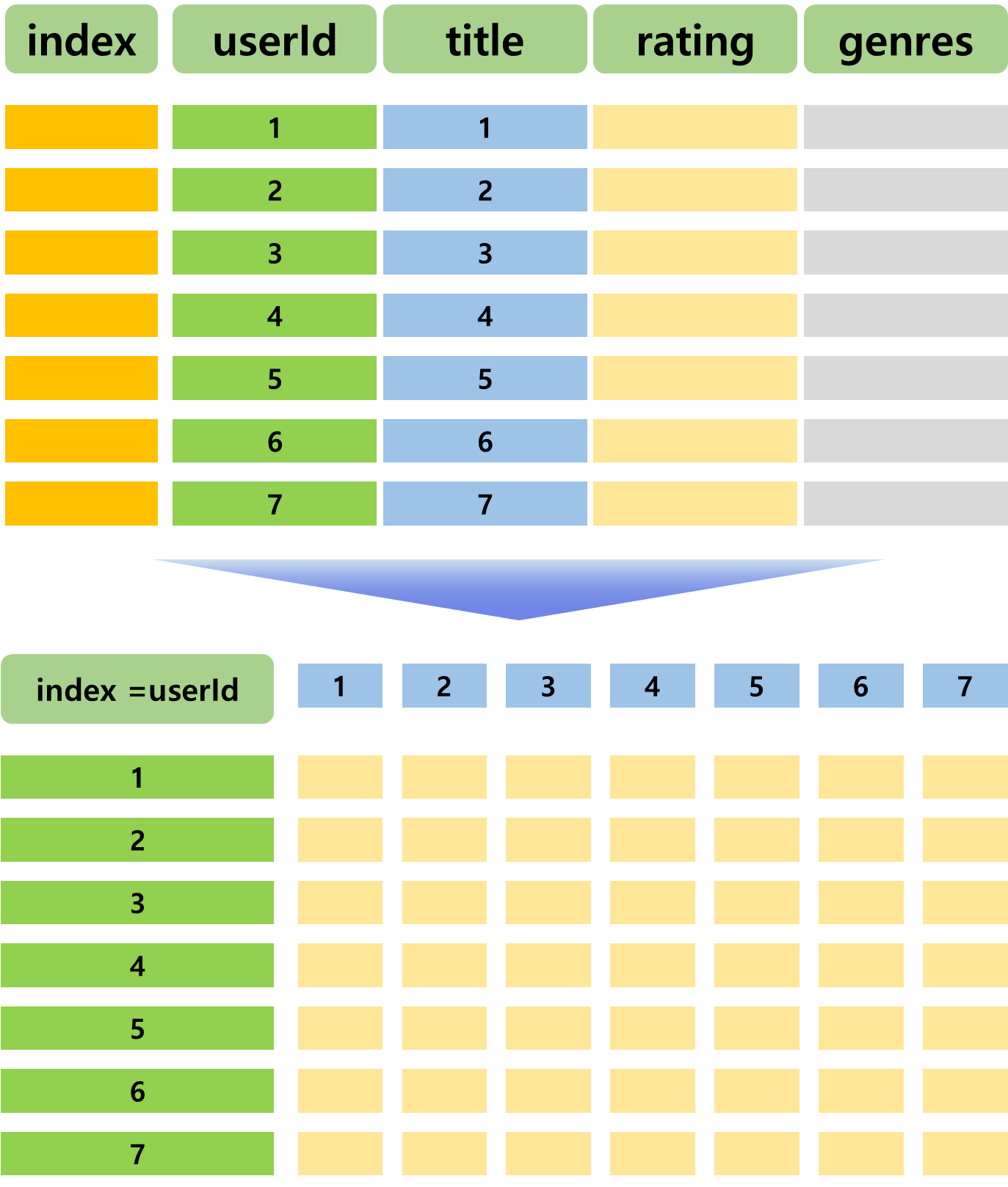
유저가 모든 영화를 본 경우는 극히 드물다. 즉 결측치가 무조건 있다는 뜻이다.
결측치를 제거해주자
# NaN 값을 모두 0 으로 변환
ratings_matrix = ratings_matrix.fillna(0)
ratings_matrix3. 영화 간 유사도 산출
분석을 위해 사용자 -영화 행렬을 영화 - 사용자 행렬로 전치 시킨다.
ratings_matrix_T = ratings_matrix.transpose() # 전치 행렬 행과 열 바꾸기
print(ratings_matrix_T.shape)
사용자들 각각이 영화에 부여한 평점을 기준으로 영화들의 유사도를 측정함
# 영화와 영화들 간 코사인 유사도 산출
from sklearn.metrics.pairwise import cosine_similarity
item_sim = cosine_similarity(ratings_matrix_T, ratings_matrix_T)
#자기자신과의 유사도를 체크
# cosine_similarity() 로 반환된 넘파이 행렬을 영화명을 매핑하여 DataFrame으로 변환
item_sim_df = pd.DataFrame(data=item_sim, index=ratings_matrix.columns,
columns=ratings_matrix.columns)
print(item_sim_df.shape)
item_sim_df.head(3)Seaborn을 이용해 100개의 영화만 시각화 해보면 다음과 같다.

4. 아이템 기반 인접 이웃 협업 필터링으로 개인화된 영화 추천
# 평점 벡터(행 벡터)와 유사도 벡터(열 벡터)를 내적(dot)해서 예측 평점을 계산하는 함수 정의
def predict_rating(ratings_arr, item_sim_arr):
ratings_pred = ratings_arr.dot(item_sim_arr) / np.array([np.abs(item_sim_arr).sum(axis=1)])
return ratings_predratings_pred = predict_rating(ratings_matrix.values , item_sim_df.values)
ratings_pred# 데이터프레임으로 변환
ratings_pred_matrix = pd.DataFrame(data=ratings_pred, index= ratings_matrix.index,
columns = ratings_matrix.columns)print(ratings_pred_matrix.shape)
ratings_pred_matrix
5.예측 평점 정확도를 판단하기 위해 오차 함수인 MSE를 이용
pred = ratings_pred[ratings_matrix.values.nonzero()].flatten()from sklearn.metrics import mean_squared_error
# 사용자가 평점을 부여한 영화에 대해서만 예측 성능 평가 MSE 를 구함.
def get_mse(pred, actual):
# Ignore nonzero terms.
pred = pred[actual.nonzero()].flatten()
actual = actual[actual.nonzero()].flatten() #nonzero
return mean_squared_error(pred, actual)
print('아이템 기반 모든 인접 이웃 MSE: ', get_mse(ratings_pred, ratings_matrix.values ))아이템 기반 모든 인접 이웃 MSE: 9.895354759094706유사도가 너무 낮은 아이템에 대해서 분석을 모두 시행하면 정확도가 떨어진다는 점을 확인할 수 있었다.
6.정확성 향상 top-N 유사도를 가진 데이터들에 대해서만 예측 평점 계산
def predict_rating_topsim(ratings_arr, item_sim_arr, n=20):
# 사용자-아이템 평점 행렬 크기만큼 0으로 채운 예측 행렬 초기화
pred = np.zeros(ratings_arr.shape)
# 사용자-아이템 평점 행렬의 열 크기만큼 Loop 수행.
for col in range(ratings_arr.shape[1]):
# 유사도 행렬에서 유사도가 큰 순으로 n개 데이터 행렬의 index 반환
top_n_items = [np.argsort(item_sim_arr[:, col])[:-n-1:-1]]
# 개인화된 예측 평점을 계산
for row in range(ratings_arr.shape[0]):
pred[row, col] = item_sim_arr[col, :][top_n_items].dot(ratings_arr[row, :][top_n_items].T)
pred[row, col] /= np.sum(np.abs(item_sim_arr[col, :][top_n_items]))
return pred# 실행시간 오래걸림....
ratings_pred = predict_rating_topsim(ratings_matrix.values , item_sim_df.values, n=20)
print('아이템 기반 인접 TOP-20 이웃 MSE: ', get_mse(ratings_pred, ratings_matrix.values ))
# 계산된 예측 평점 데이터를 DataFrame으로 생성
ratings_pred_matrix = pd.DataFrame(data=ratings_pred, index= ratings_matrix.index,
columns = ratings_matrix.columns)
ratings_pred_matrix아이템 기반 인접 TOP-20 이웃 MSE: 3.6949999176225483
7. 모델 사용 (해당 사용자가 보지 않은 영화 추천!)
해당 사용자가 보지 않은 영화중에서 유사도가 높은 영화를 추천한다.
def get_unseen_movies(ratings_matrix, userId):
# userId로 입력받은 사용자의 모든 영화정보 추출하여 Series로 반환함.
# 반환된 user_rating 은 영화명(title)을 index로 가지는 Series 객체임.
user_rating = ratings_matrix.loc[userId,:]
# user_rating이 0보다 크면 기존에 관람한 영화임. 대상 index를 추출하여 list 객체로 만듬
already_seen = user_rating[ user_rating > 0].index.tolist()
# 모든 영화명을 list 객체로 만듬.
movies_list = ratings_matrix.columns.tolist()
# list comprehension으로 already_seen에 해당하는 movie는 movies_list에서 제외함.
unseen_list = [ movie for movie in movies_list if movie not in already_seen]
return unseen_list# pred_df : 앞서 계산된 영화 별 예측 평점
# unseen_list : 사용자가 보지 않은 영화들
# top_n : 상위 n개를 가져온다.
def recomm_movie_by_userid(pred_df, userId, unseen_list, top_n=10):
# 예측 평점 DataFrame에서 사용자id index와 unseen_list로 들어온 영화명 컬럼을 추출하여
# 가장 예측 평점이 높은 순으로 정렬함.
recomm_movies = pred_df.loc[userId, unseen_list].sort_values(ascending=False)[:top_n]
return recomm_movies# 사용자가 관람하지 않는 영화명 추출
unseen_list = get_unseen_movies(ratings_matrix, 1)
# 아이템 기반의 인접 이웃 협업 필터링으로 영화 추천
recomm_movies = recomm_movie_by_userid(ratings_pred_matrix, 1, unseen_list, top_n=10)
# 평점 데이타를 DataFrame으로 생성.
recomm_movies = pd.DataFrame(data=recomm_movies.values, index=recomm_movies.index, columns=['pred_score'])
recomm_movies728x90
'딥러닝 템플릿 > 추천시스템(RS) 코드' 카테고리의 다른 글
| [추천 시스템(RS)] Neural Collaborative Filtering (0) | 2022.07.19 |
|---|---|
| [추천 시스템(RS)] Matrix Factorization (0) | 2022.07.19 |
| [추천 시스템(RS)] Surprise 라이브러리를 활용한 추천 시스템 (0) | 2022.07.19 |
| [추천 시스템(RS)] 협업 필터링 CF (Collaborate Filtering) (0) | 2022.07.16 |
| [추천 시스템(RS)] CBF 장르 기반 영화 추천 코드 (0) | 2022.07.16 |
'딥러닝 템플릿/추천시스템(RS) 코드' Related Articles
more



Comments