
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- 머신러닝
- 가격맞히기
- 흐름도
- 회귀
- 코딩
- 알고리즘
- tensorflow
- Regression
- 코딩테스트
- 프로그래머스
- PyTorch
- 템플릿
- 재귀함수
- 딥러닝
- Linear
- 추천시스템
- 연습
- DeepLearning
- CLI
- 게임
- 주식매매
- 주식연습
- API
- 파이썬
- 기초
- 선형회귀
- 크롤링
- 주가예측
- 주식
- python
Archives
- Today
- Total
코딩걸음마
[추천 시스템(RS)] 협업 필터링 CF (Collaborate Filtering) 본문
728x90
- 이웃기반 협업필터링 유사도계산, 아이템기반, 유저기반 -> 유사도; 자카드, 피어슨, 코사인
1. 데이터 불러오기
import os
import pandas as pd
import numpy as np
from math import sqrt
from tqdm import tqdm_notebook as tqdm
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_errorMovieLens
About MovieLens | Contact Us | Privacy Policy | Terms of Use version 4.5.3 2021.6.25.166 All content copyright GroupLens Research © 2021 • All rights reserved.
movielens.org
이 소스코드는 위 링크에서 데이터셋을 받아와서 사용합니다.
path = '파일경로'
ratings_df = pd.read_csv(os.path.join(path, 'ratings.csv'), encoding='utf-8')
print(ratings_df.shape)
print(ratings_df.head())(100836, 4)
userId movieId rating timestamp
0 1 1 4.0 964982703
1 1 3 4.0 964981247
2 1 6 4.0 964982224
3 1 47 5.0 964983815
4 1 50 5.0 964982931
train_df, test_df = train_test_split(ratings_df, test_size=0.2, random_state=1234)
print(train_df.shape)
print(test_df.shape)(80668, 4)
(20168, 4)2. Sparse Matrix 만들기
유저가 모든 컨텐츠에 대해서 평점을 남기는 경우는 없다.
그래서 유저별 평점 정보는 중간중간마다 결측치를 많이 가지고 있는 희소행렬의 특성을 갖는다.
분석을 위해 유저-영화 간의 평점정보를 의미하는 Sparse Matrix 를 만들어보자
생성한 Sparse matrix은 (movieid X userid) 행렬 안에 rating 정보가 담겨져있다.
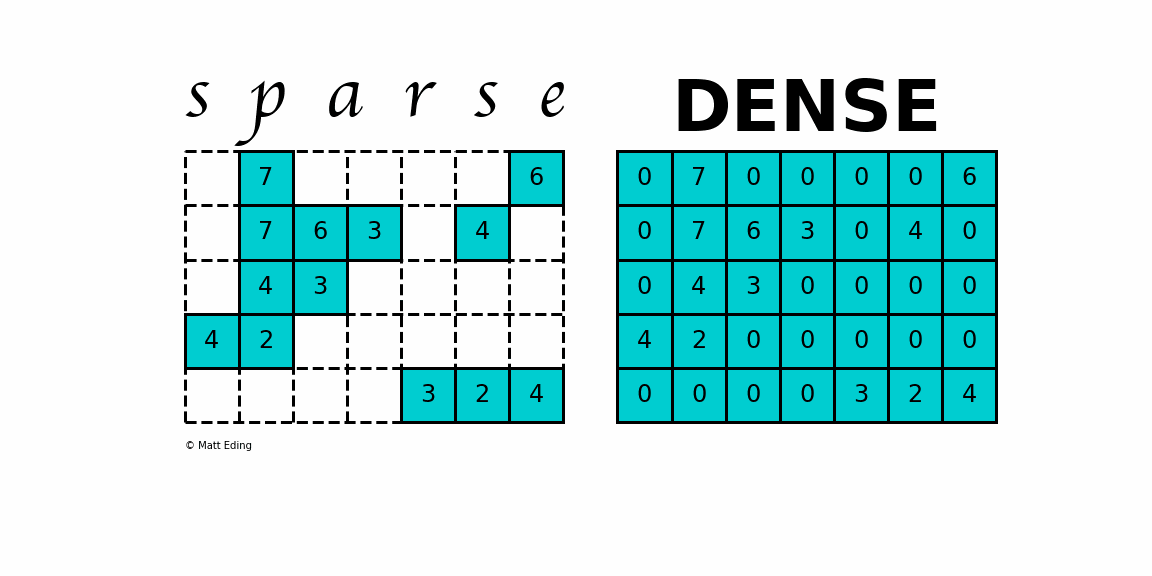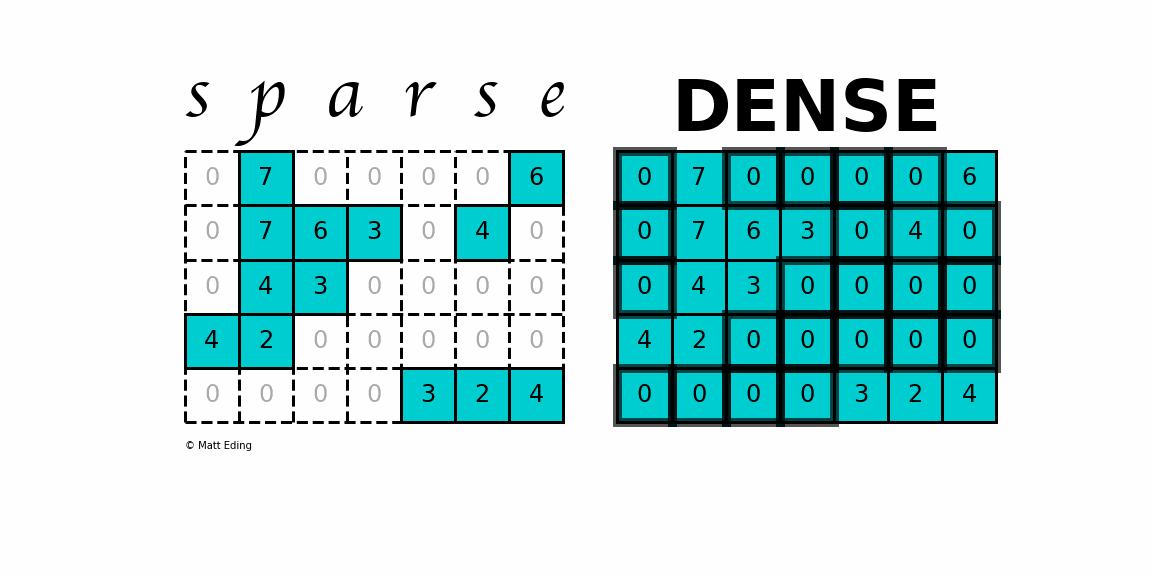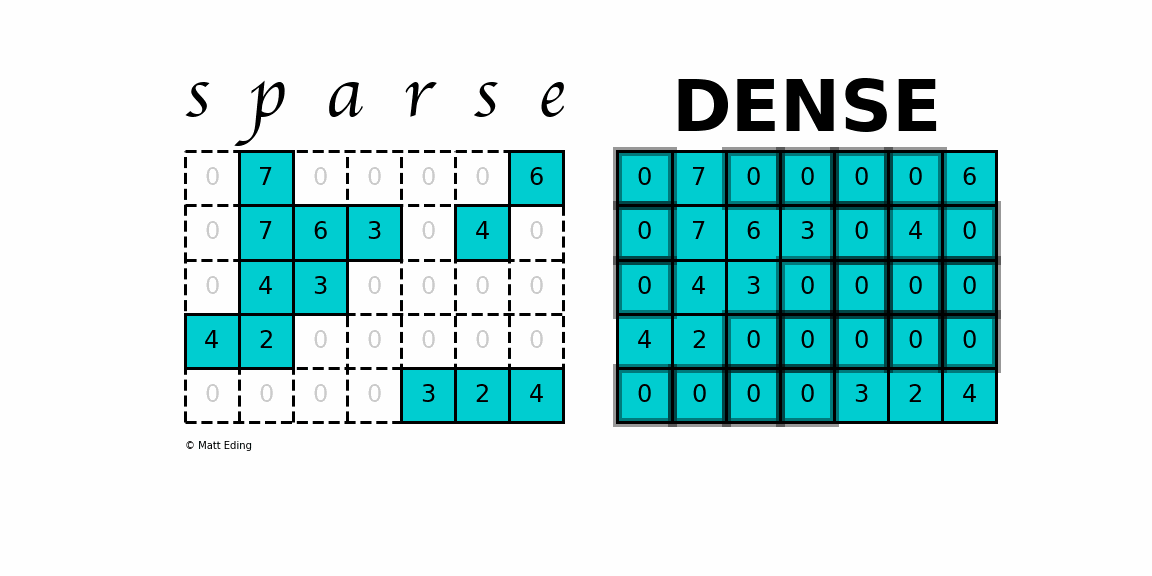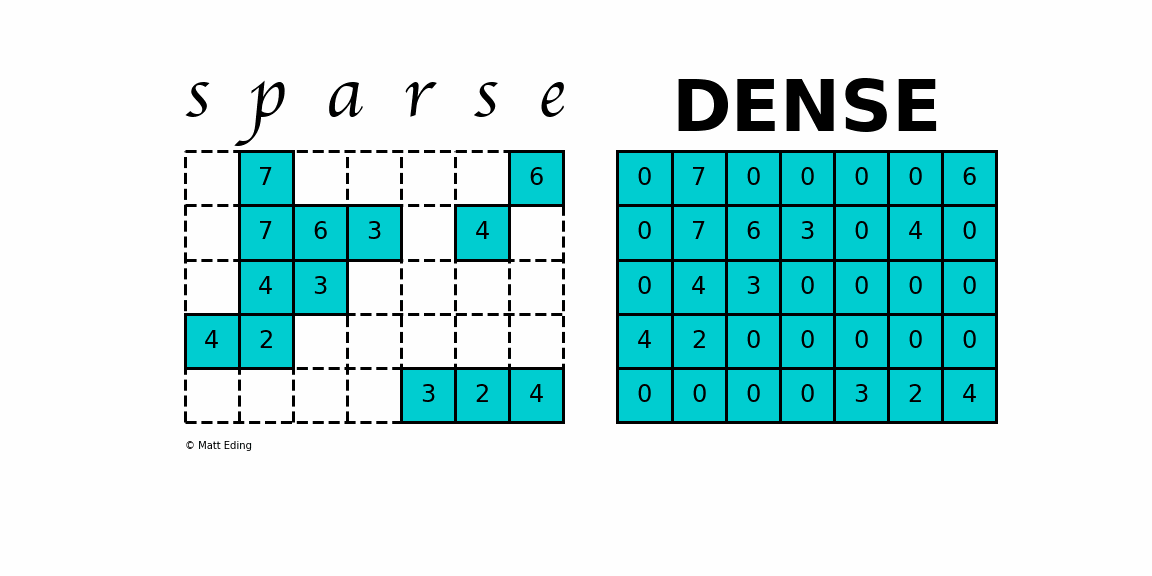
sparse_matrix = train_df.groupby('movieId').apply(lambda x: pd.Series(x['rating'].values, index=x['userId'])).unstack()
sparse_matrix.index.name = 'movieId'
sparse_matrix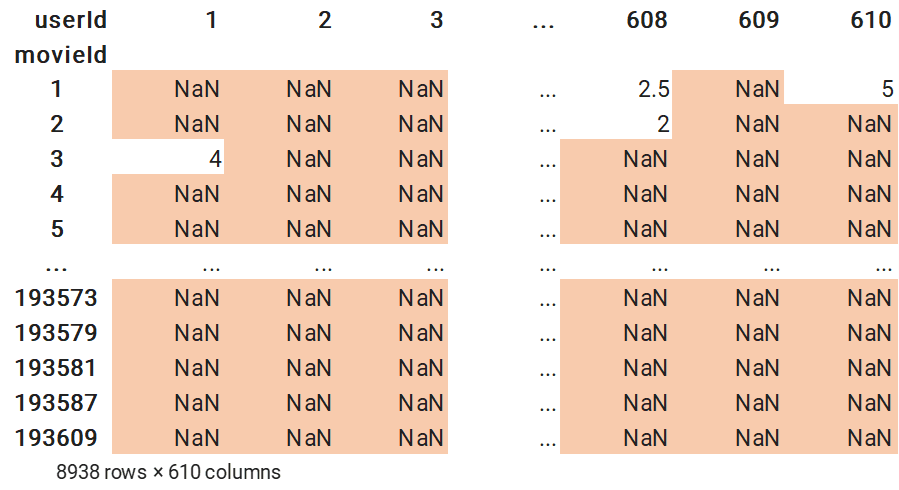
3. 코사인 유사도 활용하기(아래 다양한 방법에 대부분 사용됨)
from sklearn.metrics.pairwise import cosine_similarity
def cossim_matrix(a, b):
cossim_values = cosine_similarity(a.values, b.values)
cossim_df = pd.DataFrame(data=cossim_values, columns = a.index.values, index=a.index)
return cossim_df
4. Neighborhood-based 협업필터링 추천점수 계산하기
4-1. Item-based
4-1-1. sparse matrix 만들기
from sklearn.metrics.pairwise import cosine_similarity
def cossim_matrix(a, b):
cossim_values = cosine_similarity(a.values, b.values)
cossim_df = pd.DataFrame(data=cossim_values, columns = a.index.values, index=a.index)
return cossim_dfsparse matrix 생성 (movieid X userid) + rating
item_sparse_matrix = sparse_matrix.fillna(0)
item_sparse_matrix.shape코사인 유사도 계산
item_cossim_df = cossim_matrix(item_sparse_matrix, item_sparse_matrix)
item_cossim_dfsparse matrix (useridX movieid) + rating
userId_grouped = train_df.groupby('userId')
# index: userId, columns: total movieId
item_prediction_result_df = pd.DataFrame(index=list(userId_grouped.indices.keys()), columns=item_sparse_matrix.index)
item_prediction_result_df4-1-2. 평점 예측
for userId, group in tqdm(userId_grouped):
# user가 rating한 movieId * 전체 movieId
user_sim = item_cossim_df.loc[group['movieId']]
# user가 rating한 movieId * 1
user_rating = group['rating']
# 전체 movieId * 1
sim_sum = user_sim.sum(axis=0)
# userId의 전체 rating predictions (8938 * 1)
pred_ratings = np.matmul(user_sim.T.to_numpy(), user_rating) / (sim_sum+1)
item_prediction_result_df.loc[userId] = pred_ratings4-2. Item-based
4-2-1. sparse matrix 만들기
sparse matrix 생성 (userid X movieid) + rating
user_sparse_matrix = sparse_matrix.fillna(0).transpose()코사인 유사도 계산
user_cossim_df = cossim_matrix(user_sparse_matrix, user_sparse_matrix)
user_cossim_dfsparse matrix 생성 (movieid X userid) + rating
movieId_grouped = train_df.groupby('movieId')
user_prediction_result_df = pd.DataFrame(index=list(movieId_grouped.indices.keys()), columns=user_sparse_matrix.index)
user_prediction_result_df4-2-2. 평점 예측
for movieId, group in tqdm(movieId_grouped):
user_sim = user_cossim_df.loc[group['userId']]
user_rating = group['rating']
sim_sum = user_sim.sum(axis=0)
pred_ratings = np.matmul(user_sim.T.to_numpy(), user_rating) / (sim_sum+1)
user_prediction_result_df.loc[movieId] = pred_ratings
# return user_prediction_result_df.transpose()4-2-3. 전체 user가 모든 movie(item)에 매긴 평점 출력
# 전체 user가 모든 movieId에 매긴 평점
print(item_prediction_result_df.head())
print(user_prediction_result_df.transpose().head())
user_prediction_result_df = user_prediction_result_df.transpose()5. RMSE로 추천시스템 성능 평가하기
def evaluate(test_df, prediction_result_df):
groups_with_movie_ids = test_df.groupby(by='movieId')
groups_with_user_ids = test_df.groupby(by='userId')
intersection_movie_ids = sorted(list(set(list(prediction_result_df.columns)).intersection(set(list(groups_with_movie_ids.indices.keys())))))
intersection_user_ids = sorted(list(set(list(prediction_result_df.index)).intersection(set(groups_with_user_ids.indices.keys()))))
print(len(intersection_movie_ids))
print(len(intersection_user_ids))
compressed_prediction_df = prediction_result_df.loc[intersection_user_ids][intersection_movie_ids]
# compressed_prediction_df
# test_df에 대해서 RMSE 계산
grouped = test_df.groupby(by='userId')
result_df = pd.DataFrame(columns=['rmse'])
for userId, group in tqdm(grouped):
if userId in intersection_user_ids:
pred_ratings = compressed_prediction_df.loc[userId][compressed_prediction_df.loc[userId].index.intersection(list(group['movieId'].values))]
pred_ratings = pred_ratings.to_frame(name='rating').reset_index().rename(columns={'index':'movieId','rating':'pred_rating'})
actual_ratings = group[['rating', 'movieId']].rename(columns={'rating':'actual_rating'})
final_df = pd.merge(actual_ratings, pred_ratings, how='inner', on=['movieId'])
final_df = final_df.round(4) # 반올림
# if not final_df.empty:
# rmse = sqrt(mean_squared_error(final_df['rating_actual'], final_df['rating_pred']))
# result_df.loc[userId] = rmse
# # print(userId, rmse)
return final_dfevaluating user based prediction
evaluate(test_df, user_prediction_result_df)result_df = evaluate(test_df, user_prediction_result_df)
print(result_df)
print(f"RMSE: {sqrt(mean_squared_error(result_df['actual_rating'].values, result_df['pred_rating'].values))}")evaluating item based prediction
evaluate(test_df, item_prediction_result_df)result_df = evaluate(test_df, item_prediction_result_df)
print(result_df)
print(f"RMSE: {sqrt(mean_squared_error(result_df['actual_rating'].values, result_df['pred_rating'].values))}")
728x90
'딥러닝 템플릿 > 추천시스템(RS) 코드' 카테고리의 다른 글
| [추천 시스템(RS)] Neural Collaborative Filtering (0) | 2022.07.19 |
|---|---|
| [추천 시스템(RS)] Matrix Factorization (0) | 2022.07.19 |
| [추천 시스템(RS)] Surprise 라이브러리를 활용한 추천 시스템 (0) | 2022.07.19 |
| [추천 시스템(RS)] CF-KNN (Collaborate Filtering K-Nearest Neighbor) (0) | 2022.07.16 |
| [추천 시스템(RS)] CBF 장르 기반 영화 추천 코드 (0) | 2022.07.16 |
'딥러닝 템플릿/추천시스템(RS) 코드' Related Articles
more



Comments