
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
Tags
- 재귀함수
- CLI
- 주식매매
- 파이썬
- PyTorch
- 알고리즘
- 머신러닝
- 선형회귀
- 주식
- 흐름도
- 코딩테스트
- DeepLearning
- tensorflow
- 코딩
- 템플릿
- 가격맞히기
- Regression
- 주가예측
- 연습
- 프로그래머스
- python
- 추천시스템
- 회귀
- API
- 딥러닝
- 게임
- 크롤링
- 주식연습
- Linear
- 기초
Archives
- Today
- Total
코딩걸음마
[Selenium 4.3.0] 셀레니움의 모든 것 + 예제 본문
728x90
Selenium은 현존하는 크롤러중 가장 강력한 크롤러임이 틀림없다. 배워두면 언젠가는 써먹을 데가 있다.
이전 버전까지는 chromedriver 설치 및 복잡한 과정이 있었지만 이제 그런 걱정도 사라져서 정말 필수 모듈이 아닌가 싶다.
준비
!pip install chromedriver_autoinstaller!pip install selenium#Step 0. 필요한 모듈과 라이브러리를 로딩합니다.
import sys # 시스템
import os # 시스템
import pandas as pd # 판다스 : 데이터분석 라이브러리
import numpy as np # 넘파이 : 숫자, 행렬 데이터 라이브러리
import chromedriver_autoinstaller
from bs4 import BeautifulSoup # html 데이터를 전처리
from selenium import webdriver # 웹 브라우저 자동화
from selenium.webdriver.common.by import By
import time # 서버와 통신할 때 중간중간 시간 지연. 보통은 1초
from tqdm import tqdm_notebook # for문 돌릴 때 진행상황을 %게이지로 알려준다.
# 경고 무시
import warnings
warnings.filterwarnings('ignore')
브라우저 열기 (선택 적용)
from selenium import webdriver
driver = webdriver.Chrome('chromedriver.exe')옵션추가하기
from selenium import webdriver
options = webdriver.ChromeOptions()
driver = webdriver.Chrome('chromedriver', chrome_options=options)
driver.get('http://naver.com')
driver.implicitly_wait(3)옵션추가하기
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('headless')
options.add_argument('window-size=1920x1080')
options.add_argument("disable-gpu")
# 혹은 options.add_argument("--disable-gpu")
driver = webdriver.Chrome('chromedriver', chrome_options=options)
driver.get('http://naver.com')
driver.implicitly_wait(3)
driver.get_screenshot_as_file('naver_main_headless.png')브라우저 닫기
driver.close() #현재 탭 닫기
driver.quit() #브라우저 닫기앞으로/뒤로
driver.back() #뒤로가기
driver.forward() #앞으로가기탭 이동
driver.switch_to.window(driver.window_handles[0]) #첫번째 탭으로 이동
driver.switch_to.window(driver.window_handles[1]) #두번째 탭으로 이동
driver.switch_to.window(driver.window_handles[2]) #세번째 탭으로 이동탭 닫기
driver.switch_to.window(driver.window_handles[0]) # 먼저 해당 탭으로 이동
driver.close() # 현재 탭 닫기주요 element 유형
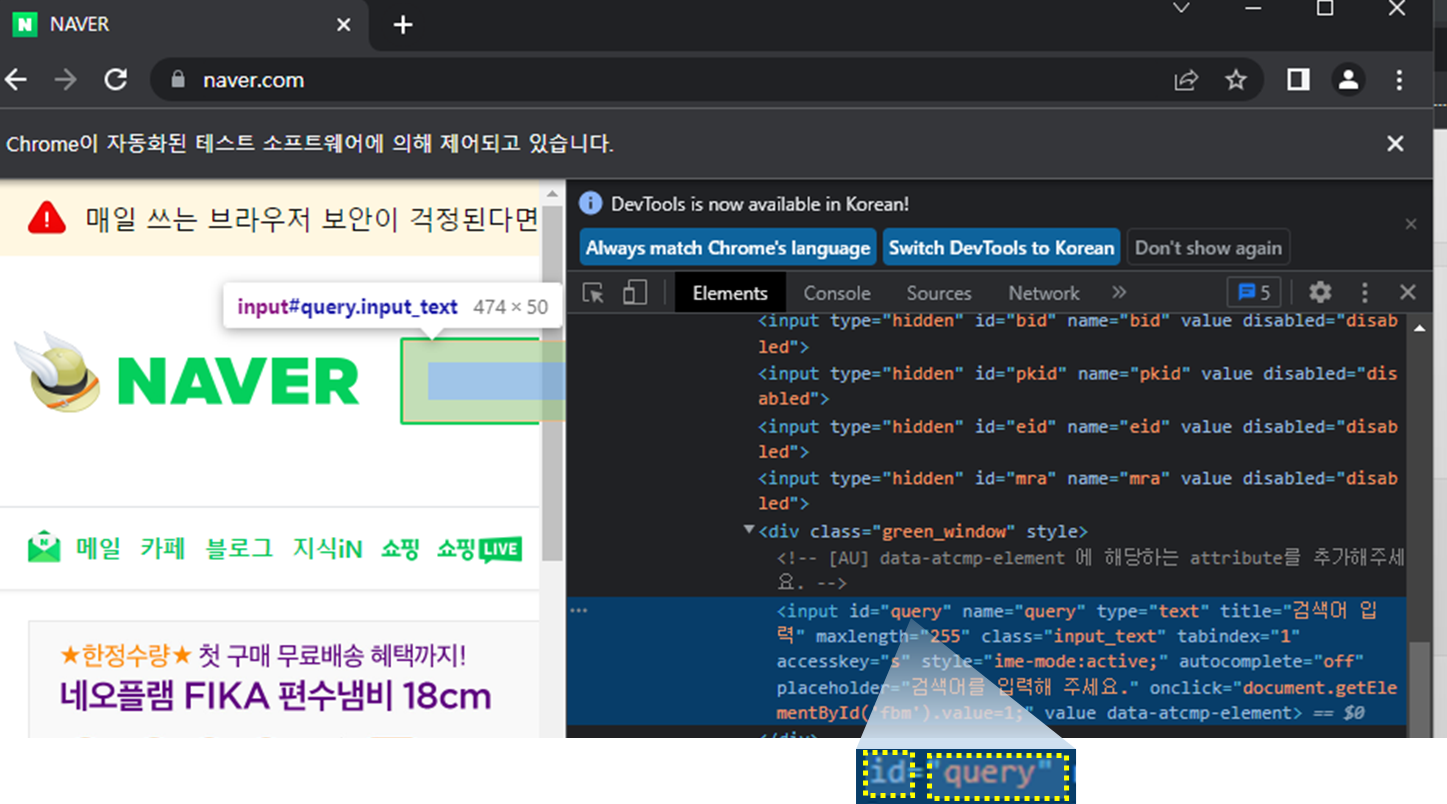
id
link text = <a태그 안에 있는 text>
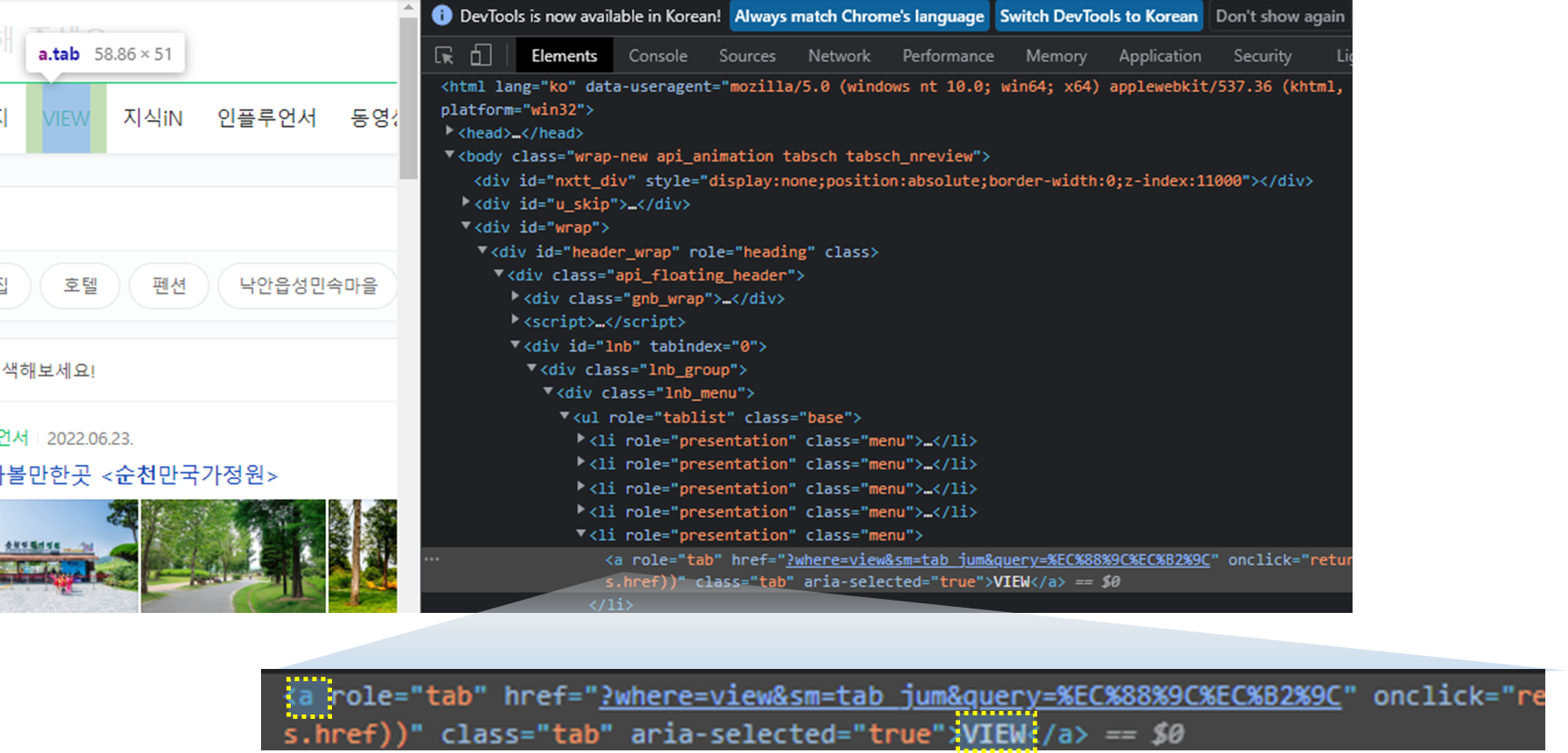
xpath = 고유 위치 코드
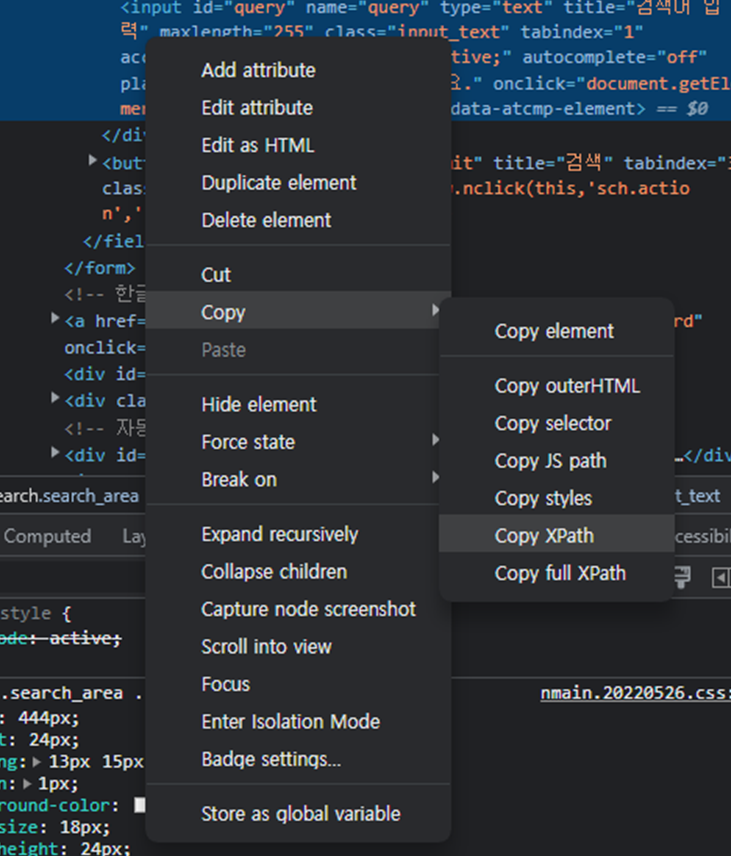
element 접근
#접근한다는 표현은 커서를 올려둔다는 표현과 같다
driver.find_element("xpath", '//button[text()="Some text"]') #xpath로 접근
driver.find_element("xpath", '//button')
driver.find_element("link text", 'Continue') #link text 안의 텍스트로 접근
driver.find_element("partial link text", 'Conti')#partial link text 안의 텍스트로 접근
driver.find_element("name", 'username') #name으로 접근
driver.find_element("tag name", 'h1') #tag name으로 접근
driver.find_element("css selector", 'p.content') #css selector로 접근 # .class
# .class 해당 클래스에 접근 #parent .class 부모 클래스 내 어딘가 있는 class에 접근
driver.find_elements("id", 'loginForm') #id 이름으로 접근
driver.find_elements("class name", 'content') #class name으로 접근element 클릭/ 텍스트 입력/ 텍스트 삭제
#클릭
driver.find_element("id","id이름").click()
#텍스트 입력
driver.find_element("id","id이름").send_keys('텍스트 입력')
#텍스트 삭제
driver.find_element("id","id이름").clear()element 텍스트 제출하기
#element = driver.find_element("id","query")
#element.send_keys("검색어")
element.submit()스크롤 내리기
# 스크롤 다운
# driver.execute_script("window.scrollTo(0, 500)")
# time.sleep(2)
# 스크롤을 밑으로 내려주는 함수
def scroll_down(driver):
driver.execute_script("window.scrollTo(0, 19431049)")
time.sleep(1)
# n: 스크롤할 횟수 설정
n = 3
i = 0
while i < n: # 이 조건이 만족되는 동안 반복 실행
scroll_down(driver) # 스크롤 다운
i = i+1경고창(alert) 다루기
#경고창으로 이동
driver.switch_to.alert
from selenium.webdriver.common.alert import Alert
Alert(driver).accept() #경고창 수락 누름
Alert(driver).dismiss() #경고창 거절 누름
print(Alert(driver).text # 경고창 텍스트 얻음쿠키 값 얻기
#쿠키값 얻기
driver.get_cookies()
#쿠키 추가
driver.add_cookie()
#쿠키 전부 삭제
driver.delete_all_cookies()
#특정 쿠기 삭제
driver.delete_cookie(cookiename)스크린샷
#캡쳐할 엘레먼트 지정
element = driver.driver.find_element_by_class_name('ico.search_submit')
#캡쳐
element.save_screenshot('image.png')뒤로가기 앞으로가기
# 뒤로가기
driver.back()
#앞으로 가기
driver.forward()단축키 입력
from selenium.webdriver.common.keys import Keys
# 컨트롤+V
driver.find_element_by_id('ke_kbd_btn').send_keys(Keys.CONTROL + 'v')
# 다른 방법
from selenium.webdriver import ActionChains
ActionChains(driver).key_down(Keys.CONTROL).send_keys('V').key_up(Keys.CONTROL).perform()
URL 수집 예제
# 블로그 글 url과 제목을 담을 리스트 생성
url_list = []
title_list = []
# URL_크롤링 기본 구조
target = ".css selector 넣을것"
raw = driver.find_elements("css selector",target)
raw[0].get_attribute('href')
# 제목 크롤링 시작
for j in raw:
title = j.text
title_list.append(title)
print(title)
# 크롤링한 selenium 객체인 raw get_attribute 함수를 이용, url 추출(href 속성값만 뽑아내기)하기
for i in raw:
url = i.get_attribute('href')
url_list.append(url)
time.sleep(1)
print("")
print('url갯수: ', len(url_list))
print('title갯수: ', len(title_list))
# 수집된 url_list, title_list로 판다스 데이터프레임 만들기
df = pd.DataFrame({'url':url_list, 'title':title_list})
df.to_csv("title-url.csv", encoding='utf-8-sig',index= False)
수집한 URL을 활용한 크롤링
import sys
import os
import pandas as pd
import numpy as np# "url_list.csv" 불러오기
url_load = pd.read_csv("title-url.csv")
#url_load = url_load.drop("col명", axis=1) # 불필요한 칼럼 삭제
num_list = len(url_load)
print(num_list)
url_load수집한 URL을 활용한 크롤링(1개만 크롤링 해보기)
# 글 하나 띄우기
i = 1
url = url_load['url'][i]
driver = webdriver.Chrome(chrome_path)
driver.get(url) # 글 띄우기수집한 URL을 활용한 크롤링
주의) iframe 접근 #frame으로 막혀있는 경우
driver.switch_to.frame('mainFrame') # 개별 블로그 내용을 담을 딕셔너리 생성
dict = {}
target_info = {}
# 제목 크롤링 시작
overlays = ".se-module.se-module-text.se-title-text"
tit = driver.find_element("css selector",overlays) # title
title = tit.text
# 글쓴이 크롤링 시작
overlays = ".nick"
nick = driver.find_element("css selector",overlays) # nickname
nickname = nick.text
# 날짜 크롤링
overlays = ".se_publishDate.pcol2"
date = driver.find_element("css selector",overlays) # datetime
datetime = date.text
# 내용 크롤링 셀레니움 객체에 담음
overlays = ".se-component.se-text.se-l-default"
contents = driver.find_elements("css selector",overlays) # contents
# 각각의 문단에 접근해서 내용을 리스트에 담고,
# join 함수를 이용해서 하나의 문장으로 이어붙이기
content_list = []
for content in contents:
content_list.append(content.text)
content_str = ' '.join(content_list) # content_str
# 글 하나는 target_info라는 딕셔너리에 담기게 되고,
target_info['title'] = title
target_info['nickname'] = nickname
target_info['datetime'] = datetime
target_info['content'] = content_str
# 개별 블로그 내용을 딕셔너리에 저장
dict[i] = target_info수집한 URL을 활용한 크롤링(모두 크롤링 해보기)
dict = {} # 전체 크롤링 데이터를 담을 그릇
# 수집할 글 갯수 정하기
number = 10
# 수집한 url 돌면서 데이터 수집
for i in tqdm_notebook(range(0, number)):
# 글 띄우기
url = url_load['url'][i]
driver = webdriver.Chrome(chrome_path, options=options)
driver.get(url) # 글 띄우기
# 크롤링
try :
# iframe 접근
driver.switch_to.frame('mainFrame')
target_info = {} # 개별 블로그 내용을 담을 딕셔너리 생성
# 제목 크롤링 시작
overlays = ".se-module.se-module-text.se-title-text"
tit = driver.find_element("css selector",overlays) # title
title = tit.text
# 글쓴이 크롤링 시작
overlays = ".nick"
nick = driver.find_element("css selector",overlays) # nickname
nickname = nick.text
# 날짜 크롤링
overlays = ".se_publishDate.pcol2"
date = driver.find_element("css selector",overlays) # datetime
datetime = date.text
# 내용 크롤링
overlays = ".se-component.se-text.se-l-default"
contents = driver.find_elements("css selector",overlays) # contents
content_list = []
for content in contents:
content_list.append(content.text)
content_str = ' '.join(content_list) # content_str
# 글 하나는 target_info라는 딕셔너리에 담기게 되고,
target_info['title'] = title
target_info['nickname'] = nickname
target_info['datetime'] = datetime
target_info['content'] = content_str
# 각각의 글은 dict라는 딕셔너리에 담기게 됩니다.
dict[i] = target_info
time.sleep(1)
# 크롤링이 성공하면 글 제목을 출력하게 되고,
print(i, title)
# 글 하나 크롤링 후 크롬 창을 닫습니다.
driver.close()
# 에러나면 현재 크롬창을 닫고 다음 글(i+1)로 이동합니다.
except:
driver.close()
time.sleep(1)
continue
# 판다스로 만들기
import pandas as pd
result_df = pd.DataFrame.from_dict(dict, 'index')
# 저장하기
result_df.to_csv("blog_content.csv", encoding='utf-8-sig',index=False)
time.sleep(3)
print('수집한 글 갯수: ', len(dict))
print(dict)# 판다스로 만들기
import pandas as pd
result_df = pd.DataFrame.from_dict(dict, 'index')
# 엑셀로 저장하기
result_df.to_csv("blog_content.csv", encoding='utf-8-sig')728x90
'꿀팁 소스코드 저장소' 카테고리의 다른 글
| [Bootstrap] 이미지 조정 방법 (0) | 2023.02.14 |
|---|---|
| 구글 Vision API로 이미지 내 텍스트를 인식하기! (파이썬) (0) | 2022.10.25 |
'꿀팁 소스코드 저장소' Related Articles
more

Comments