
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 주식
- 알고리즘
- python
- 파이썬
- 가격맞히기
- 머신러닝
- PyTorch
- 추천시스템
- 딥러닝
- 회귀
- 게임
- 주식연습
- 템플릿
- Linear
- tensorflow
- 기초
- 주식매매
- CLI
- 코딩
- 연습
- 크롤링
- 재귀함수
- API
- 코딩테스트
- Regression
- 흐름도
- 선형회귀
- 프로그래머스
- 주가예측
- DeepLearning
- Today
- Total
코딩걸음마
[추천 시스템(RS)] Surprise 라이브러리를 활용한 추천 시스템 본문
Surprise 라이브러리는 복잡한 추천시스템을 간단하게(scikit learn과 비슷하게) 구현해놓은 라이브러리입니다.
추천시스템을 간단하게 구현할 수 있지만, 추천 알고리즘을 이해한 후에 사용하는 것이 좋다.
0. 라이브러리 설치
!pip install scikit-surprise윈도우 사용자는 여기서부터 에러가 뜨는데 이때는 visual studio buildtools를 설치한 후에 라이브러리 설치를 진행해야한다.
https://visualstudio.microsoft.com/ko/downloads/
Visual Studio Tools 다운로드 - Windows, Mac, Linux용 무료 설치
Visual Studio IDE 또는 VS Code를 무료로 다운로드하세요. Windows 또는 Mac에서 Visual Studio Professional 또는 Enterprise Edition을 사용해 보세요.
visualstudio.microsoft.com
1. 내장된 무비렌즈 데이터로 Surprise 패키지 사용
import surprise
from surprise import SVD # MF(행렬 분해) 특이값 분해
from surprise import Dataset # 내장 데이터 불러오는 라이브러리
from surprise import accuracy # accuracy의 rmse메소드로 예측 에러 평가
from surprise.model_selection import train_test_split # 학습셋, 테스트셋 분리1-1. 데이터 가져온 후, train-test split data
# 영화 데이터 10만개가 들어있는 "ml-100k" 데이터 로드
data = Dataset.load_builtin('ml-100k')
# 로드된 데이터를 학습셋, 테스트셋(20%)으로 나누기
trainset, testset = train_test_split(data, test_size=.20, random_state=42)1-2. 행렬 분해 알고리즘(특이값 분해)으로 SVD 객체를 생성하고 학습 수행
#algo 객체에 행렬 분해(SVD)로 학습된 모델이 저장됨.
algo = SVD()
algo.fit(trainset)1-3. 테스트 데이터에 예상 평점 데이터 예측
# 테스트 데이터 사용자 아이템에 대한 예상 평점 리스트 구하기
predictions = algo.test( testset )
print('prediction type :',type(predictions), ' size:',len(predictions))
predictions[:5]Out
[Prediction(uid='907', iid='143', r_ui=5.0, est=4.906966365752232, details={'was_impossible': False}),
Prediction(uid='371', iid='210', r_ui=4.0, est=4.333964235369792, details={'was_impossible': False}),
Prediction(uid='218', iid='42', r_ui=4.0, est=3.448597772345096, details={'was_impossible': False}),
Prediction(uid='829', iid='170', r_ui=4.0, est=3.6783240639958024, details={'was_impossible': False}),
Prediction(uid='733', iid='277', r_ui=1.0, est=3.1246056492655794, details={'was_impossible': False})]uid = user id , iid = item id, r_ui = user가 item에 대하여 매긴 rating, est = 추정 평점
+) 간단하게 확인하게
[(pred.uid, pred.iid, pred.r_ui, pred.est) for pred in predictions[:5] ]Out
[('907', '143', 5.0, 4.906966365752232),
('371', '210', 4.0, 4.333964235369792),
('218', '42', 4.0, 3.448597772345096),
('829', '170', 4.0, 3.6783240639958024),
('733', '277', 1.0, 3.1246056492655794)]1-4. 예측 평점들의 에러 확인
accuracy.rmse(predictions)Out
RMSE: 0.9381
0.9380752634340338
1-5 predict 메소드를 활용한 개별 사용자, 아이템에 대한 예측 평점 계산
user_id, item_id를 무조건 문자열 type으로 입력해야 함.
uid = str(100)
iid = str(100)
pred = algo.predict(uid, iid)
print(pred)user: 100 item: 100 r_ui = None est = 3.92 {'was_impossible': False}
2. 실제 영화 평점 데이터로 surprise 패키지 사용해보기
from surprise import SVD # 행렬 분해 알고리즘
from surprise import Dataset # 내장 데이터 불러오는 라이브러리
from surprise import accuracy # rmse로 예측 에러 평가
from surprise.model_selection import train_test_split # 학습셋, 테스트셋 분리2-1. 데이터 가져온 후, train-test split data
import pandas as pd
#surprise를 적용하려면 header를 없애줘야 한다.
ratings = pd.read_csv('ratings.csv')print(ratings.shape)
ratings.head()Out
(100836, 4)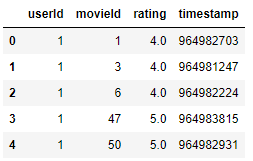
surprise 내장함수인 Reader를 사용하여 불러올 데이터에 컬럼명을 구분해주어야한다.
또한 rating_scale=(0.5, 5) 평점 범위를 설정해주어야한다.
from surprise import Reader,
reader = Reader(line_format='user item rating timestamp', sep=',', rating_scale=(0.5, 5))
# 데이터 로딩하기
data = Dataset.load_from_file('ratings.csv', reader=reader)# 데이터를 학습셋, 테스트셋으로 나누기
trainset, testset = train_test_split(data, test_size=.2, random_state=42)2-2. 행렬 분해 알고리즘(특이값 분해)으로 SVD 객체를 생성하고 학습 수행
# SVD 알고리즘 적용(잠재 요인의 차원 수 = 50개, random_state )
잠재요인(latent matrix)행렬의 차원을 정함 잠재요인 행렬이 클수록 정확도는 올라가지만 연산이 많아짐
algo = SVD(n_factors=50, random_state=42)
algo.fit(trainset)
2-3. 테스트 데이터에 예상 평점 데이터 예측
predictions = algo.test(testset)
predictions[:5]Out
[Prediction(uid='63', iid='2000', r_ui=3.0, est=3.5016267817280697, details={'was_impossible': False}),
Prediction(uid='31', iid='788', r_ui=2.0, est=3.2840758900255937, details={'was_impossible': False}),
Prediction(uid='159', iid='6373', r_ui=4.0, est=2.804939396068158, details={'was_impossible': False}),
Prediction(uid='105', iid='81564', r_ui=3.0, est=3.9326180027723914, details={'was_impossible': False}),
Prediction(uid='394', iid='480', r_ui=3.0, est=3.3135580105479114, details={'was_impossible': False})]2-4. 예측 평점들의 에러 확인
# RMSE 평가
accuracy.rmse(predictions)Out
RMSE: 0.8682
0.86819529271435162-5 predict 메소드를 활용한 개별 사용자, 아이템에 대한 예측 평점 계산
user_id, item_id를 무조건 문자열 type으로 입력해야 함.
uid = str(100)
iid = str(100)
pred = algo.predict(uid, iid)
print(pred)
user: 100 item: 100 r_ui = None est = 3.36 {'was_impossible': False}
3. Cross Validation(교차 검증)과 GridSearchCV(하이퍼 파라미터 튜닝)
cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=횟수, verbose=True)
from surprise.model_selection import cross_validate # 교차 검증 : 과적합없이 모델 학습이 가능하다.
# Pandas DataFrame에서 Surprise Dataset으로 데이터 로딩
ratings = pd.read_csv('ratings.csv')
# 데이터 샘플링 (2천만 건 데이터를 20만 건으로)
ratings = ratings.sample(frac=0.01)
reader = Reader(rating_scale=(0.5, 5.0))
data = Dataset.load_from_df(ratings[['userId', 'movieId', 'rating']], reader)
# SVD 알고리즘
algo = SVD(random_state=0)
# 교차 검증
cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=10, verbose=True)Out
Evaluating RMSE, MAE of algorithm SVD on 10 split(s).
Fold 1 Fold 2 Fold 3 Fold 4 Fold 5 Fold 6 Fold 7 Fold 8 Fold 9 Fold 10 Mean Std
RMSE (testset) 0.9329 0.9993 1.0791 1.0867 0.9922 1.0243 0.8922 0.9900 1.1282 1.0562 1.0181 0.0685
MAE (testset) 0.7628 0.7555 0.8476 0.8291 0.8124 0.7922 0.7032 0.8431 0.8970 0.8464 0.8089 0.0535
Fit time 0.05 0.06 0.05 0.06 0.06 0.05 0.05 0.05 0.05 0.05 0.05 0.00
Test time 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
{'test_rmse': array([0.93287886, 0.99933529, 1.07911549, 1.08672902, 0.99221313,
1.02432193, 0.89218751, 0.9900444 , 1.12823875, 1.05615647]),
'test_mae': array([0.76283932, 0.75551644, 0.84756277, 0.82912701, 0.81238001,
0.79224057, 0.70320174, 0.84309762, 0.89695821, 0.84642138]),
'fit_time': (0.05197262763977051,
0.056000471115112305,
0.04802346229553223,
0.056000471115112305,
0.05700278282165527,
0.04901432991027832,
0.05303597450256348,
0.05096697807312012,
0.05200386047363281,
0.05299878120422363),
'test_time': (0.0010006427764892578,
0.0010342597961425781,
0.0009760856628417969,
0.0010361671447753906,
0.0009982585906982422,
0.000993490219116211,
0.0009970664978027344,
0.0010001659393310547,
0.001996278762817383,
0.0010006427764892578)}
4. 그리드 서치 CV 이용
from surprise.model_selection import GridSearchCV
# 최적화할 파라미터들을 딕셔너리 형태로 지정.
param_grid = {'n_epochs': [20, 40, 60], 'n_factors': [50, 100, 200] }
# GridSearchCV 세팅 : CV를 3개 폴드 세트로 지정, 성능 평가는 rmse, mse 로 수행 하도록 GridSearchCV 구성
gs = GridSearchCV(SVD, param_grid, measures=['rmse', 'mae'], cv=3)
gsOut
<surprise.model_selection.search.GridSearchCV at 0x2a22b62cd30>결과를 출력하면 객체가 반환되는데 반환된 객체에 best_score, best_params메소드를 사용하면
제일 좋은 epochs와 잠재요인행렬의 n_factor를 구할 수 있다.
# GridSearchCV로 학습
gs.fit(data)
# 최고 RMSE Evaluation 점수와 그때의 하이퍼 파라미터
print(gs.best_score['rmse'])
print(gs.best_params['rmse'])
# 20만 건 데이터 기준 실행시간 (원본 데이터 2천만 건이면 8분~10분 정도 걸림)1.0155670371249206
{'n_epochs': 60, 'n_factors': 50}
Wall time: 2.5 s
5. Surprise 를 이용한 개인화 영화 추천 시스템 구축
특정 사용자가 아직 보지 않은 영화 중에서 추천해주는 추천시스템을 만들어보자
from surprise.dataset import DatasetAutoFolds # 데이터 세트 전체를 학습 데이터로 사용할 수 있게 해주는 라이브러리
reader = Reader(line_format='user item rating timestamp', sep=',', rating_scale=(0.5, 5))
# DatasetAutoFolds 클래스를 ratings_noh.csv 파일 기반으로 생성.
data_folds = DatasetAutoFolds(ratings_file='ratings.csv', reader=reader)
# 전체 데이터를 학습데이터로 생성함.
trainset = data_folds.build_full_trainset()# SVD 협업필터링으로 추천모델 학습(하이퍼 파라미터는 앞서 그리드서치로 구한 것들)
algo = SVD(n_epochs=60, n_factors=50, random_state=0)
algo.fit(trainset)
영화정보 DataFrame 불러오기
# 영화에 대한 상세 속성 정보 DataFrame로딩
movies = pd.read_csv('movies.csv')
movies.head()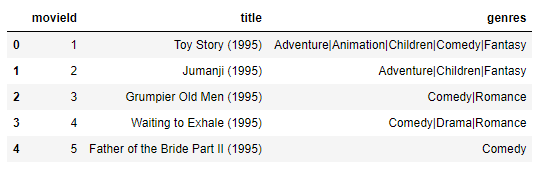
5번 유저가 본 영화 리스트 확인
movieIds = ratings[ratings['userId']==5]['movieId']
movieIdsSeries([], Name: movieId, dtype: int64)본 영화가 없다..
다시 5번 유저의 영화 DataFrame을 정의해준다.
# userId=5 의 movieId 확인.
movieIds = ratings[ratings['userId']==5]
movieIds본 영화가 없으니, 가장 평점이 높을것 같은 영화를 출력해주면된다.
하나의 영화로 예시를 들어보면
print(movies[movies['movieId']==30]) movieId title genres
29 30 Shanghai Triad (Yao a yao yao dao waipo qiao) ... Crime|Drama30번 영화를 5번 유저에게 추천한다면
# predict 메소드를 사용해서 예측 평점 구하기
uid = str(5)
iid = str(30)
pred = algo.predict(uid, iid, verbose=True)user: 5 item: 30 r_ui = None est = 2.84 {'was_impossible': False}2.84점을 얻을 수 있다.
아래 함수를 활용하여 한 유저가 평점을 매긴 영화 수, 추전대상 영화수 (전체 영화수 - 평점매긴수) , 전체영화수를 출력한다.
def get_unseen_surprise(ratings, movies, userId):
#입력값으로 들어온 userId에 해당하는 사용자가 평점을 매긴 모든 영화를 리스트로 생성
seen_movies = ratings[ratings['userId']== userId]['movieId'].tolist()
# 모든 영화들의 movieId를 리스트로 생성.
total_movies = movies['movieId'].tolist()
# 모든 영화들의 movieId중 이미 평점을 매긴 영화의 movieId를 제외하여 리스트로 생성
unseen_movies= [movie for movie in total_movies if movie not in seen_movies]
print('평점 매긴 영화수:',len(seen_movies), '추천대상 영화수:',len(unseen_movies), \
'전체 영화수:',len(total_movies))
return unseen_movies
unseen_movies = get_unseen_surprise(ratings, movies, 9)def recomm_movie_by_surprise(algo, userId, unseen_movies, top_n=10):
# 알고리즘 객체의 predict() 메서드를 평점이 없는 영화(27243개)에 반복 수행한 후 결과를 list 객체로 저장
predictions = [algo.predict(str(userId), str(movieId)) for movieId in unseen_movies]
# predictions list 객체는 surprise의 Predictions 객체를 원소로 가지고 있음.
# [Prediction(uid='9', iid='1', est=3.69), Prediction(uid='9', iid='2', est=2.98),,,,]
# 이를 est 값으로 정렬하기 위해서 아래의 sortkey_est 함수를 정의함.
# sortkey_est 함수는 list 객체의 sort() 함수의 키 값으로 사용되어 정렬 수행.
def sortkey_est(pred):
return pred.est
# sortkey_est( ) 반환값의 내림 차순으로 정렬 수행하고 top_n개의 최상위 값 추출.
predictions.sort(key=sortkey_est, reverse=True)
top_predictions= predictions[:top_n]
# top_n으로 추출된 영화의 정보 추출. 영화 아이디, 추천 예상 평점, 제목 추출
top_movie_ids = [ int(pred.iid) for pred in top_predictions]
top_movie_rating = [ pred.est for pred in top_predictions]
top_movie_titles = movies[movies.movieId.isin(top_movie_ids)]['title']
top_movie_preds = [ (id, title, rating) for id, title, rating in zip(top_movie_ids, top_movie_titles, top_movie_rating)]
return top_movie_preds
unseen_movies = get_unseen_surprise(ratings, movies, 5)
top_movie_preds = recomm_movie_by_surprise(algo, 5, unseen_movies, top_n=20)
print("")
print(f'Top-20 추천 영화 리스트')
for top_movie in top_movie_preds:
print(top_movie[1], ":", top_movie[2])Out
평점 매긴 영화수: 0 추천대상 영화수: 9742 전체 영화수: 9742
Top-20 추천 영화 리스트
City of Lost Children, The (Cité des enfants perdus, La) (1995) : 4.990718479475137
Hoop Dreams (1994) : 4.824264979261401
Pulp Fiction (1994) : 4.804060944974705
In the Name of the Father (1993) : 4.6082228391027495
Schindler's List (1993) : 4.604937291733954
Snow White and the Seven Dwarfs (1937) : 4.549056258993766
Godfather, The (1972) : 4.543705567059189
Reservoir Dogs (1992) : 4.522740275199627
Paths of Glory (1957) : 4.508964839522082
Goodfellas (1990) : 4.484576657955622
Great Escape, The (1963) : 4.477707936637026
Unforgiven (1992) : 4.4691174116858114
Young Frankenstein (1974) : 4.46346229492448
American Beauty (1999) : 4.451183657984832
Fight Club (1999) : 4.451107562443208
Trial, The (Procès, Le) (1962) : 4.447663059997404
Eternal Sunshine of the Spotless Mind (2004) : 4.436344973997466
In Bruges (2008) : 4.4356249280933
X-Men: First Class (2011) : 4.427412135588302
Submarine (2010) : 4.412816077530302'딥러닝 템플릿 > 추천시스템(RS) 코드' 카테고리의 다른 글
| [추천 시스템(RS)] Neural Collaborative Filtering (0) | 2022.07.19 |
|---|---|
| [추천 시스템(RS)] Matrix Factorization (0) | 2022.07.19 |
| [추천 시스템(RS)] 협업 필터링 CF (Collaborate Filtering) (0) | 2022.07.16 |
| [추천 시스템(RS)] CF-KNN (Collaborate Filtering K-Nearest Neighbor) (0) | 2022.07.16 |
| [추천 시스템(RS)] CBF 장르 기반 영화 추천 코드 (0) | 2022.07.16 |



