
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- DeepLearning
- Regression
- 게임
- 주가예측
- 회귀
- 프로그래머스
- 크롤링
- 알고리즘
- 가격맞히기
- 주식연습
- Linear
- 주식
- 주식매매
- tensorflow
- 재귀함수
- 흐름도
- CLI
- 파이썬
- 딥러닝
- 템플릿
- 선형회귀
- 머신러닝
- 연습
- PyTorch
- 코딩
- API
- 추천시스템
- 코딩테스트
- 기초
- python
Archives
- Today
- Total
코딩걸음마
[추천 시스템(RS)] Neural Collaborative Filtering 본문
728x90
- 기존 Linear Matrix Factorization의 한계점을 보완한다
- Neural Net 기반의 Cllaborative Filltering으로 non-linear 한 부분을 설명할 수 있도록 한다.
- user와 item의 관계를 보다 복잡하게 모델링 할 수 있다.
원리
user의 interation data가 있는지 없는지에 따라 0, 1 로 여부를 표시한 후,
0과 1중에 확률이 높은 결과값을 반환하는 함수를 활용한다.

import os
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
import math
from torch import nn, optim
import torch
import torch.nn.functional as F
from torch.autograd import Variable
from tqdm import tqdm
import warnings
warnings.filterwarnings("ignore")
1. 데이터 불러오기 및 train-test set 분리
사용할 Dataset은 KMRD Dataset을 사용하였다.
data_path = '파일경로'Dataset 분리 함수로 정의하여 사용한다.
def read_data(data_path):
df = pd.read_csv(os.path.join(data_path,'rates.csv'))
train_df, val_df = train_test_split(df, test_size=0.2, random_state=42, shuffle=True)
return train_df, val_df# 학습할 영화 데이터 구분
train_df, val_df = read_data(data_path)
train_df
colums 구성은 user movie rate time으로 구성되어있다.
데이터의 분포를 시각화하여 점검해보자
fig, ax = plt.subplots(1, 2, sharex='col', sharey='row', figsize=(12,7))
ax = ax.ravel()
train_df['rate'].hist(ax=ax[0])
val_df['rate'].hist(ax=ax[1])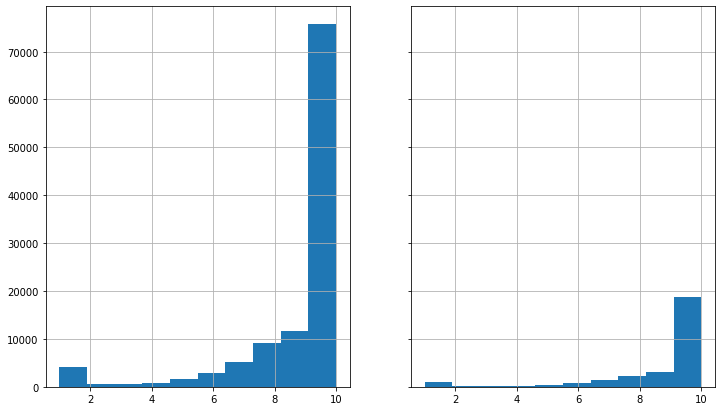
train_df['rate'].describe()Out
count 112568.000000
mean 8.948369
std 2.114602
min 1.000000
25% 9.000000
50% 10.000000
75% 10.000000
max 10.000000
Name: rate, dtype: float64절반 이상이 10점인 데이터분포를 가지고 있다.
len(train_df['movie'].unique()) , len(train_df['user'].unique())Out
(595, 44692)595개의 영화에 대한 44,692명의 평점이 학습대상임을 확인했다.
movie dataframe 불러오기
# Load all related dataframe
movies_df = pd.read_csv(os.path.join(data_path, 'movies.txt'), sep='\t', encoding='utf-8')
movies_df = movies_df.set_index('movie')
#movies_df
castings_df = pd.read_csv(os.path.join(data_path, 'castings.csv'), encoding='utf-8')
countries_df = pd.read_csv(os.path.join(data_path, 'countries.csv'), encoding='utf-8')
genres_df = pd.read_csv(os.path.join(data_path, 'genres.csv'), encoding='utf-8')
# Get genre information
genres = [(list(set(x['movie'].values))[0], '/'.join(x['genre'].values)) for index, x in genres_df.groupby('movie')]
combined_genres_df = pd.DataFrame(data=genres, columns=['movie', 'genres'])
combined_genres_df = combined_genres_df.set_index('movie')
# Get castings information
castings = [(list(set(x['movie'].values))[0], x['people'].values) for index, x in castings_df.groupby('movie')]
combined_castings_df = pd.DataFrame(data=castings, columns=['movie','people'])
combined_castings_df = combined_castings_df.set_index('movie')
# Get countries for movie information
countries = [(list(set(x['movie'].values))[0], ','.join(x['country'].values)) for index, x in countries_df.groupby('movie')]
combined_countries_df = pd.DataFrame(data=countries, columns=['movie', 'country'])
combined_countries_df = combined_countries_df.set_index('movie')
movies_df = pd.concat([movies_df, combined_genres_df, combined_castings_df, combined_countries_df], axis=1)
movies_df.head()
# 영화 데이터의 메타 정보를 확인한다
movieName_dict = movies_df.to_dict()['title']
genres_dict = movies_df.to_dict()['genres']Dataset Loader 클래스 생성
class DatasetLoader:
def __init__(self, data_path):
self.train_df, val_temp_df = read_data(data_path)
self.min_rating = min(self.train_df.rate)
self.max_rating = self.train_df.rate.max()
self.unique_users = self.train_df.user.unique()
self.num_users = len(self.unique_users)
self.user_to_index = {original: idx for idx, original in enumerate(self.unique_users)}
# 0 1 0 0 0 ... 0
self.unique_movies = self.train_df.movie.unique()
self.num_movies = len(self.unique_movies)
self.movie_to_index = {original: idx for idx, original in enumerate(self.unique_movies)}
self.val_df = val_temp_df[val_temp_df.user.isin(self.unique_users) & val_temp_df.movie.isin(self.unique_movies)]
def generate_trainset(self):
# user 0, 0, 0, 1,2, 3,3, -> movie: 0,0,0,0,0,0,
X_train = pd.DataFrame({'user': self.train_df.user.map(self.user_to_index),
'movie': self.train_df.movie.map(self.movie_to_index)})
y_train = self.train_df['rate'].astype(np.float32)
return X_train, y_train
def generate_valset(self):
X_val = pd.DataFrame({'user': self.val_df.user.map(self.user_to_index),
'movie': self.val_df.movie.map(self.movie_to_index)})
y_val = self.val_df['rate'].astype(np.float32)
return X_val, y_valModel Structure
class FeedForwardEmbedNN(nn.Module):
def __init__(self, n_users, n_movies, hidden, dropouts, n_factors, embedding_dropout):
super().__init__()
self.user_emb = nn.Embedding(n_users, n_factors)
self.movie_emb = nn.Embedding(n_movies, n_factors)
self.drop = nn.Dropout(embedding_dropout)
self.hidden_layers = nn.Sequential(*list(self.generate_layers(n_factors*2, hidden, dropouts)))
self.fc = nn.Linear(hidden[-1], 1)
def generate_layers(self, n_factors, hidden, dropouts):
assert len(dropouts) == len(hidden)
idx = 0
while idx < len(hidden):
if idx == 0:
yield nn.Linear(n_factors, hidden[idx])
else:
yield nn.Linear(hidden[idx-1], hidden[idx])
yield nn.ReLU()
yield nn.Dropout(dropouts[idx])
idx += 1
def forward(self, users, movies, min_rating=0.5, max_rating=5):
concat_features = torch.cat([self.user_emb(users), self.movie_emb(movies)], dim=1)
x = F.relu(self.hidden_layers(concat_features))
# 0과 1사이의 숫자로 나타낸다
out = torch.sigmoid(self.fc(x))
# rating으로 변환한다
out = (out * (max_rating - min_rating)) + min_rating
return out
def predict(self, users, movies):
# return the score
output_scores = self.forward(users, movies)
return output_scoresclass BatchIterator:
def __init__(self, X, y, batch_size=32, shuffle=True):
X, y = np.asarray(X), np.asarray(y)
if shuffle:
index = np.random.permutation(X.shape[0])
X, y = X[index], y[index]
self.X = X
self.y = y
self.batch_size = batch_size
self.shuffle = shuffle
self.n_batches = int(math.ceil(X.shape[0] // batch_size))
self._current = 0
def __iter__(self):
return self
def __next__(self):
return self.next()
def next(self):
if self._current >= self.n_batches:
raise StopIteration()
k = self._current
self._current += 1
bs = self.batch_size
return self.X[k * bs:(k + 1) * bs], self.y[k * bs:(k + 1) * bs]def batches(X, y, bs=32, shuffle=True):
for x_batch, y_batch in BatchIterator(X, y, bs, shuffle):
x_batch = torch.LongTensor(x_batch)
y_batch = torch.FloatTensor(y_batch)
yield x_batch, y_batch.view(-1, 1)Train model
def model_train(ds, config):
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
X_train, y_train = ds.generate_trainset()
X_valid, y_valid = ds.generate_valset()
print(f'TrainSet Info: {ds.num_users} users, {ds.num_movies} movies')
model = FeedForwardEmbedNN(
n_users=ds.num_users, n_movies=ds.num_movies,
n_factors=config['num_factors'], hidden=config['hidden_layers'],
embedding_dropout=config['embedding_dropout'], dropouts=config['dropouts']
)
model.to(device)
batch_size = config['batch_size']
num_epochs = config['num_epochs']
max_patience = config['total_patience']
num_patience = 0
best_loss = np.inf
criterion = nn.MSELoss(reduction='sum')
criterion.to(device)
optimizer = optim.Adam(model.parameters(), lr=config['learning_rate'], weight_decay=config['weight_decay'])
result = dict()
for epoch in tqdm(range(num_epochs)):
training_loss = 0.0
for batch in batches(X_train, y_train, shuffle=True, bs=batch_size):
x_batch, y_batch = [b.to(device) for b in batch]
optimizer.zero_grad()
# with torch.no_grad() 와 동일한 syntax 입니다
with torch.set_grad_enabled(True):
outputs = model(x_batch[:, 0], x_batch[:, 1], ds.min_rating, ds.max_rating)
loss = criterion(outputs, y_batch)
loss.backward()
optimizer.step()
training_loss += loss.item()
result['train'] = training_loss / len(X_train)
# Apply Early Stopping criteria and save best model params
val_outputs = model(torch.LongTensor(X_valid.user.values).to(device),
torch.LongTensor(X_valid.movie.values).to(device), ds.min_rating, ds.max_rating)
val_loss = criterion(val_outputs.to(device), torch.FloatTensor(y_valid.values).view(-1, 1).to(device))
result['val'] = float((val_loss / len(X_valid)).data)
if val_loss < best_loss:
print('Save new model on epoch: %d' % (epoch + 1))
best_loss = val_loss
result['best_loss'] = val_loss
torch.save(model.state_dict(), config['save_path'])
num_patience = 0
else:
num_patience += 1
print(f'[epoch: {epoch+1}] train: {result["train"]} - val: {result["val"]}')
if num_patience >= max_patience:
print(f"Early Stopped after epoch {epoch+1}")
break
return resultdef model_valid(user_id_list, movie_id_list, data_path):
dataset = DatasetLoader(data_path)
processed_test_input_df = pd.DataFrame({
'user_id': [dataset.user_to_index[x] for x in user_id_list],
'movie_id': [dataset.movie_to_index[x] for x in movie_id_list]
})
# 학습한 모델 load하기
my_model = FeedForwardEmbedNN(dataset.num_users, dataset.num_movies,
config['hidden_layers'], config['dropouts'], config['num_factors'], config['embedding_dropout'])
my_model.load_state_dict(torch.load('params.data'))
prediction_outputs = my_model.predict(users=torch.LongTensor(processed_test_input_df.user_id.values),
movies=torch.LongTensor(processed_test_input_df.movie_id.values))
return prediction_outputsdataset = DatasetLoader(data_path)config = {
"num_factors": 16,
"hidden_layers": [64, 32, 16],
"embedding_dropout": 0.03,
"dropouts": [0.3, 0.3, 0.3],
"learning_rate": 1e-3,
"weight_decay": 1e-5,
"batch_size": 16,
"num_epochs": 3,
"total_patience": 30,
"save_path": "params.data"
}
model_train(dataset, config)Out
TrainSet Info: 44692 users, 595 movies
33%|███▎ | 1/3 [00:21<00:42, 21.09s/it]Save new model on epoch: 1
[epoch: 1] train: 4.335322794146853 - val: 4.273048400878906
67%|██████▋ | 2/3 [00:38<00:19, 19.20s/it]Save new model on epoch: 2
[epoch: 2] train: 3.79635754700375 - val: 3.992642641067505
100%|██████████| 3/3 [00:56<00:00, 18.97s/it]Save new model on epoch: 3
[epoch: 3] train: 3.3121653504981543 - val: 3.9417591094970703
{'best_loss': tensor(80687.8047, device='cuda:0', grad_fn=<MseLossBackward0>),
'train': 3.3121653504981543,
'val': 3.9417591094970703}
movie_id_list = [10050, 10001, 10002]
user_id = 11242
user_id_list = [user_id] * len(movie_id_list)
pred_results = [float(x) for x in model_valid(user_id_list, movie_id_list, data_path)]
result_df = pd.DataFrame({
'userId': user_id_list,
'movieId': movie_id_list,
# 'movieName': [movieName_dict[x] for x in movie_id_list],
# 'genres': [genres_dict[x] for x in movie_id_list],
'pred_ratings': pred_results
})
result_df.sort_values(by='pred_ratings', ascending=False)
728x90
'딥러닝 템플릿 > 추천시스템(RS) 코드' 카테고리의 다른 글
| [추천 시스템(RS)] Wide & Deep Learning for Recommender System (0) | 2022.07.20 |
|---|---|
| [추천 시스템(RS)] Factorization Machine (0) | 2022.07.19 |
| [추천 시스템(RS)] Matrix Factorization (0) | 2022.07.19 |
| [추천 시스템(RS)] Surprise 라이브러리를 활용한 추천 시스템 (0) | 2022.07.19 |
| [추천 시스템(RS)] 협업 필터링 CF (Collaborate Filtering) (0) | 2022.07.16 |
'딥러닝 템플릿/추천시스템(RS) 코드' Related Articles
more



Comments