
250x250
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- 알고리즘
- CLI
- 가격맞히기
- 흐름도
- 주가예측
- 딥러닝
- 회귀
- 주식연습
- PyTorch
- 크롤링
- DeepLearning
- 주식
- 기초
- 선형회귀
- 게임
- Linear
- 코딩
- tensorflow
- 주식매매
- 재귀함수
- 머신러닝
- 파이썬
- API
- python
- 추천시스템
- 코딩테스트
- Regression
- 프로그래머스
- 연습
- 템플릿
Archives
- Today
- Total
코딩걸음마
[추천 시스템(RS)] Matrix Factorization 본문
728x90

Matrix Factorization의 자세한 설명은 아래링크를 확인하자
https://developers.google.com/machine-learning/recommendation/collaborative/matrix
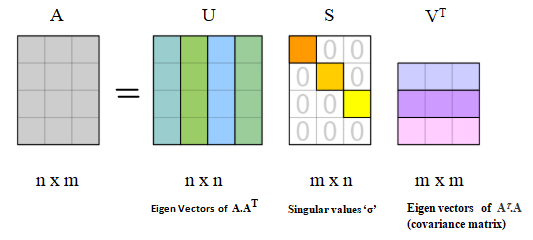
요약하면 Matrix Factorization(MF)는 User와 Item 간의 평가 정보를 나타내는 Rating Matrix를 User Latent Matrix와 Item Latent Matrix로 분해하는 기법을 말한다.
Rating Matrix는 (User의 수) * (Item의 수)로 구성된 행렬이다.
각 칸에는 각 유저가 기록한 해당 아이템에 대한 평가가 기록된다. 평점 Data는 Sparse Matrix(희소행렬)가 되기 마련인데, MF는 이러한 행렬 분해 과정에서 이러한 빈칸을 채울만한 평점을 예측하는 과정이라고 볼 수 있다.
SVD
import os
import pandas as pd
import numpy as np
from math import sqrt
from tqdm import tqdm_notebook as tqdm
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt1. 데이터 불러오기
path = '파일경로'
ratings_df = pd.read_csv(os.path.join(path, '파일명.csv'), encoding='utf-8')
print(ratings_df.shape)
print(ratings_df.head())Out
(100836, 4)
userId movieId rating timestamp
0 1 1 4.0 964982703
1 1 3 4.0 964981247
2 1 6 4.0 964982224
3 1 47 5.0 964983815
4 1 50 5.0 964982931약 10만개의 평점데이터를 활용하여 분석해봅시다.
사용한 데이터는 movielens Data입니다.
2. Train-Test set 분리
train_df, test_df = train_test_split(ratings_df, test_size=0.2, random_state=1234)
print(train_df.shape)
print(test_df.shape)이 예시에서는 train data중 1000개만 사용했습니다.
train_df = train_df[:1000] #1000개만 사용하자
3. Sparse Matrix 생성
sparse_matrix = train_df.groupby('movieId').apply(lambda x: pd.Series(x['rating'].values, index=x['userId'])).unstack()
sparse_matrix.index.name = 'movieId'
sparse_matrix = sparse_matrix.fillna(0)
# fill sparse matrix with average of movie ratings
sparse_matrix_withmovie = sparse_matrix.apply(lambda x: x.fillna(x.mean()), axis=1)
# # fill sparse matrix with average of user ratings
# sparse_matrix_withuser = sparse_matrix.apply(lambda x: x.fillna(x.mean()), axis=0)#DataFrame --> numpy기준으로 모두 바꿔주어야 함
sparse_matrix = sparse_matrix.to_numpy()
sparse_matrix_withmovie = sparse_matrix_withmovie.to_numpy()
sparse_matrixOut
array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])
4. Matrix Factorization 실행
class MF():
def __init__(self, R, K, alpha, beta, iterations):
"""
Perform matrix factorization to predict empty
entries in a matrix.
Arguments
- R (ndarray) : user-item rating matrix
- K (int) : number of latent dimensions
- alpha (float) : learning rate
- beta (float) : regularization parameter
"""
self.R = R
self.num_users, self.num_items = R.shape
self.K = K
self.alpha = alpha #learning rate
self.beta = beta #regularization term
self.iterations = iterations #epoch
def train(self):
# Initialize user and item latent feature matrice
#User - item 관계의 matrix를 생성
self.P = np.random.normal(scale=1./self.K, size=(self.num_users, self.K))
self.Q = np.random.normal(scale=1./self.K, size=(self.num_items, self.K))
# Initialize the biases
self.b_u = np.zeros(self.num_users)
self.b_i = np.zeros(self.num_items)
self.b = np.mean(self.R[np.where(self.R != 0)])
# Create a list of training samples
# 0보다 큰경우에만 traing sample로 사용한다.
# 0 은 관측되지 않은 data로 간주함
self.samples = [
(i, j, self.R[i, j])
for i in range(self.num_users)
for j in range(self.num_items)
if self.R[i, j] > 0
]
# Perform stochastic gradient descent for number of iterations
training_process = []
for i in range(self.iterations):
np.random.shuffle(self.samples)
self.sgd()
mse = self.mse()
training_process.append((i, mse))
# if (i+1) % 10 == 0:
print("Iteration: %d ; error = %.4f" % (i+1, mse))
return training_process
def mse(self):
"""
A function to compute the total mean square error
"""
xs, ys = self.R.nonzero()
predicted = self.full_matrix()
error = 0
for x, y in zip(xs, ys):
error += pow(self.R[x, y] - predicted[x, y], 2)
return np.sqrt(error)
def sgd(self):
"""
Perform stochastic graident descent
"""
for i, j, r in self.samples:
# Computer prediction and error
prediction = self.get_rating(i, j)
e = (r - prediction)
# Update biases
self.b_u[i] += self.alpha * (e - self.beta * self.b_u[i])
self.b_i[j] += self.alpha * (e - self.beta * self.b_i[j])
# Create copy of row of P since we need to update it but use older values for update on Q
P_i = self.P[i, :][:]
# Update user and item latent feature matrices
self.P[i, :] += self.alpha * (e * self.Q[j, :] - self.beta * self.P[i,:])
self.Q[j, :] += self.alpha * (e * P_i - self.beta * self.Q[j,:])
def get_rating(self, i, j):
"""
Get the predicted rating of user i and item j
"""
prediction = self.b + self.b_u[i] + self.b_i[j] + self.P[i, :].dot(self.Q[j, :].T)
return prediction
def full_matrix(self):
"""
Computer the full matrix using the resultant biases, P and Q
"""
return self.b + self.b_u[:,np.newaxis] + self.b_i[np.newaxis:,] + self.P.dot(self.Q.T)4 -1. Train MF
mf = MF(sparse_matrix, K=600, alpha=0.1, beta=0.01, iterations=30)mf = MF(sparse_matrix, K=잠재요인 행렬차원 수, alpha=learning rate, beta=정규화 정도, iterations=epochs)
training_process = mf.train()Out
Iteration: 1 ; error = 25.2549
Iteration: 2 ; error = 21.6429
Iteration: 3 ; error = 19.1403
Iteration: 4 ; error = 17.2063
....
Iteration: 19 ; error = 5.0117
Iteration: 20 ; error = 4.5855
Iteration: 21 ; error = 4.1998
Iteration: 22 ; error = 3.8510
Iteration: 23 ; error = 3.5384
Iteration: 24 ; error = 3.2573
Iteration: 25 ; error = 3.0125
Iteration: 26 ; error = 2.7913
Iteration: 27 ; error = 2.5980
Iteration: 28 ; error = 2.4223
Iteration: 29 ; error = 2.2667
Iteration: 30 ; error = 2.1289
mf.full_matrix()Out
array([[4.91006501, 5.00318751, 4.58333199, ..., 4.00383646, 3.7725352 ,
4.17535522],
[4.13546034, 4.2276779 , 3.80725154, ..., 3.22806173, 3.02965593,
3.35595899],
[3.68031736, 3.77251815, 3.35199727, ..., 2.77277242, 2.55578367,
2.9140627 ],
...,
[4.07696013, 4.1691228 , 3.74852484, ..., 3.16960148, 2.95167586,
3.31130491],
[4.40725566, 4.49976066, 4.0790016 , ..., 3.4997886 , 3.28313181,
3.6412904 ],
[3.88154557, 3.97378338, 3.55307772, ..., 2.97406229, 2.75847232,
3.11285759]])4 -2. 시각화
x = [x for x, y in training_process]
y = [y for x, y in training_process]
plt.figure(figsize=((16,4)))
plt.plot(x, y)
plt.xticks(x, x)
plt.xlabel("Iterations")
plt.ylabel("Mean Square Error")
plt.grid(axis="y")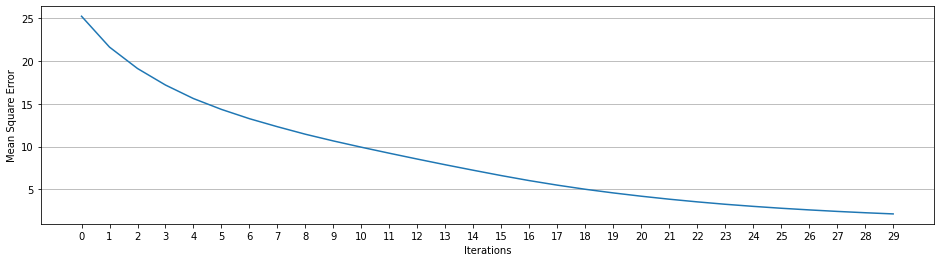
728x90
'딥러닝 템플릿 > 추천시스템(RS) 코드' 카테고리의 다른 글
| [추천 시스템(RS)] Factorization Machine (0) | 2022.07.19 |
|---|---|
| [추천 시스템(RS)] Neural Collaborative Filtering (0) | 2022.07.19 |
| [추천 시스템(RS)] Surprise 라이브러리를 활용한 추천 시스템 (0) | 2022.07.19 |
| [추천 시스템(RS)] 협업 필터링 CF (Collaborate Filtering) (0) | 2022.07.16 |
| [추천 시스템(RS)] CF-KNN (Collaborate Filtering K-Nearest Neighbor) (0) | 2022.07.16 |
'딥러닝 템플릿/추천시스템(RS) 코드' Related Articles
more



Comments